Aprendizaje de reglas de asociación
Aprendizaje de reglas de asociación es un método popular y bien investigado para descubrir interesantes relaciones entre variables en grandes bases de datos. Se pretende identificar reglas fuertes descubiertas en bases de datos utilizando diferentes medidas de interés.[1] Basado en el concepto de reglas fuertes, Rakesh Agrawal et al.[2] introdujo reglas de Asociación para descubrir las regularidades entre productos de datos de transacciones a gran escala grabados por punto de venta Sistemas (POS) en los supermercados. Por ejemplo, la regla  encontrado en las ventas de datos de un supermercado indicaría que si un cliente compra las cebollas y papas juntos, él o ella es probable que también comprar carne de la hamburguesa. Dicha información puede utilizarse como base para las decisiones sobre las actividades de marketing tales como, por ejemplo, promocional fijación de precios o colocaciones de productos. Además del ejemplo anterior de Análisis de la cesta de la compra las reglas de asociación se emplean hoy en muchas áreas de aplicación incluyendo Minería de uso Web, detección de intrusos, Producción continua, y Bioinformática. En contraste con minería de secuencia, aprendizaje de reglas de asociación típicamente no tiene en cuenta el orden de elementos dentro de una transacción o a través de las transacciones.
encontrado en las ventas de datos de un supermercado indicaría que si un cliente compra las cebollas y papas juntos, él o ella es probable que también comprar carne de la hamburguesa. Dicha información puede utilizarse como base para las decisiones sobre las actividades de marketing tales como, por ejemplo, promocional fijación de precios o colocaciones de productos. Además del ejemplo anterior de Análisis de la cesta de la compra las reglas de asociación se emplean hoy en muchas áreas de aplicación incluyendo Minería de uso Web, detección de intrusos, Producción continua, y Bioinformática. En contraste con minería de secuencia, aprendizaje de reglas de asociación típicamente no tiene en cuenta el orden de elementos dentro de una transacción o a través de las transacciones.
Contenido
- 1 Definición
- 2 Conceptos útiles
- 3 Proceso
- 4 Historia
- 5 Medidas alternativas de interés
- 6 Asociaciones estadísticamente sonidas
- 7 Algoritmos
- 7.1 Algoritmo Apriori
- 7.2 Algoritmo de eclat
- 7.3 Algoritmo de FP-crecimiento
- 7.4 Otros
- 7.4.1 AprioriDP
- 7.4.2 Asociación regla minería algoritmo basado en contexto
- 7.4.3 Nodo conjunto basado en algoritmos
- 7.4.4 Procedimiento de GUHA ASSOC
- 7.4.5 Búsqueda de OPUS
- 8 Lore
- 9 Otros tipos de explotación minera de la Asociación
- 10 Véase también
- 11 Referencias
- 12 Enlaces externos
- 12.1 Bibliografías
- 12.2 Implementaciones
Definición
| Identificador de la transacción | leche | pan | mantequilla | cerveza |
|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 |
| 3 | 0 | 0 | 0 | 1 |
| 4 | 1 | 1 | 1 | 0 |
| 5 | 0 | 1 | 0 | 0 |
Siguiendo la definición original de Agrawal et al.[2] el problema de la explotación minera de regla de asociación se define como: dejar  ser un conjunto de
ser un conjunto de  atributos binarios llamados artículos. Dejar
atributos binarios llamados artículos. Dejar  ser un conjunto de transacciones llamado el base de datos. Cada transacción en
ser un conjunto de transacciones llamado el base de datos. Cada transacción en  tiene un identificador de transacción y contiene un subconjunto de los elementos
tiene un identificador de transacción y contiene un subconjunto de los elementos  . A regla se define como una implicación de la forma
. A regla se define como una implicación de la forma 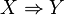 donde
donde  y
y  . Los conjuntos de artículos (para corto itemsets)
. Los conjuntos de artículos (para corto itemsets)  y
y  se llaman antecedente (lado izquierdo o LHS) y consecuente (mano derecha o RHS) de la regla respectivamente.
se llaman antecedente (lado izquierdo o LHS) y consecuente (mano derecha o RHS) de la regla respectivamente.
Para ilustrar los conceptos, utilizamos un pequeño ejemplo del dominio de supermercado. Es el conjunto de ítems 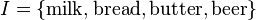 y una pequeña base de datos que contiene los elementos (1 códigos presencia y 0 ausencia de un elemento en una transacción) se muestra en la tabla a la derecha. Podría ser una regla de ejemplo para el supermercado
y una pequeña base de datos que contiene los elementos (1 códigos presencia y 0 ausencia de un elemento en una transacción) se muestra en la tabla a la derecha. Podría ser una regla de ejemplo para el supermercado 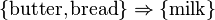 lo que significa que si se compran pan y mantequilla, los clientes también compran leche.
lo que significa que si se compran pan y mantequilla, los clientes también compran leche.
Nota: este ejemplo es extremadamente pequeño. En aplicaciones prácticas, una regla necesita un apoyo de varias cien transacciones antes de que pueda ser considerado estadísticamente significativo, y bases de datos contienen a menudo miles o millones de transacciones.
Conceptos útiles
Para seleccionar reglas interesantes del conjunto de todas las reglas posibles, pueden utilizarse las restricciones sobre diversas medidas de importancia e interés. Las limitaciones más conocidas son los umbrales mínimos de apoyo y confianza.
- El apoyo
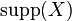 de un conjunto de ítems
de un conjunto de ítems  se define como la proporción de las transacciones en el conjunto de datos que contienen el conjunto de ítems. En la base de datos de ejemplo, el conjunto de ítems
se define como la proporción de las transacciones en el conjunto de datos que contienen el conjunto de ítems. En la base de datos de ejemplo, el conjunto de ítems  cuenta con un apoyo de
cuenta con un apoyo de 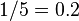 puesto que ocurre en el 20% de todas las transacciones (operaciones en 1 de cada 5).
puesto que ocurre en el 20% de todas las transacciones (operaciones en 1 de cada 5).
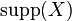 de un conjunto de ítems
de un conjunto de ítems  cuenta con un apoyo de
cuenta con un apoyo de 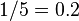 puesto que ocurre en el 20% de todas las transacciones (operaciones en 1 de cada 5).
puesto que ocurre en el 20% de todas las transacciones (operaciones en 1 de cada 5).- El confianza de una regla se define
 . Por ejemplo, la regla
. Por ejemplo, la regla 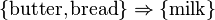 tiene una confianza de
tiene una confianza de 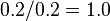 en la base de datos, lo que significa que para el 100% de las transacciones que contengan mantequilla la regla es correcta (100% de las veces que un cliente compra mantequilla y pan, la leche es comprado también). Ten cuidado al leer la expresión: supp(X∪Y) significa "soporte para las ocurrencias de transacciones donde X e Y aparecen", no"soporte para las ocurrencias de transacciones donde Ya sea X o Y aparece", la última interpretación que se deriven porque Unión conjunto es equivalente a disyunción lógica. El argumento de
en la base de datos, lo que significa que para el 100% de las transacciones que contengan mantequilla la regla es correcta (100% de las veces que un cliente compra mantequilla y pan, la leche es comprado también). Ten cuidado al leer la expresión: supp(X∪Y) significa "soporte para las ocurrencias de transacciones donde X e Y aparecen", no"soporte para las ocurrencias de transacciones donde Ya sea X o Y aparece", la última interpretación que se deriven porque Unión conjunto es equivalente a disyunción lógica. El argumento de  es un conjunto de condiciones previas y así llega a ser más restrictiva que crece (en lugar de más inclusivo).
es un conjunto de condiciones previas y así llega a ser más restrictiva que crece (en lugar de más inclusivo).
 . Por ejemplo, la regla
. Por ejemplo, la regla 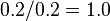 en la base de datos, lo que significa que para el 100% de las transacciones que contengan mantequilla la regla es correcta (100% de las veces que un cliente compra mantequilla y pan, la leche es comprado también). Ten cuidado al leer la expresión: supp(X∪Y) significa "soporte para las ocurrencias de transacciones donde X e Y aparecen", no"soporte para las ocurrencias de transacciones donde Ya sea X o Y aparece", la última interpretación que se deriven porque Unión conjunto es equivalente a disyunción lógica. El argumento de
en la base de datos, lo que significa que para el 100% de las transacciones que contengan mantequilla la regla es correcta (100% de las veces que un cliente compra mantequilla y pan, la leche es comprado también). Ten cuidado al leer la expresión: supp(X∪Y) significa "soporte para las ocurrencias de transacciones donde X e Y aparecen", no"soporte para las ocurrencias de transacciones donde Ya sea X o Y aparece", la última interpretación que se deriven porque Unión conjunto es equivalente a disyunción lógica. El argumento de  es un conjunto de condiciones previas y así llega a ser más restrictiva que crece (en lugar de más inclusivo).
es un conjunto de condiciones previas y así llega a ser más restrictiva que crece (en lugar de más inclusivo).- Confianza puede interpretarse como una estimación de la probabilidad
 , la probabilidad de encontrar el lado derecho de la regla en las transacciones con la condición de que estas transacciones también contienen la LHS.[3]
, la probabilidad de encontrar el lado derecho de la regla en las transacciones con la condición de que estas transacciones también contienen la LHS.[3]
 , la probabilidad de encontrar el lado derecho de la regla en las transacciones con la condición de que estas transacciones también contienen la LHS.
, la probabilidad de encontrar el lado derecho de la regla en las transacciones con la condición de que estas transacciones también contienen la LHS.- El Levante de una regla se define como
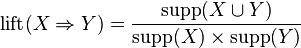 o la relación entre el apoyo observado para que esperar si X e Y se independiente. La regla
o la relación entre el apoyo observado para que esperar si X e Y se independiente. La regla  tiene una elevación de
tiene una elevación de  .
.
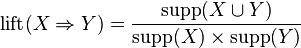 o la relación entre el apoyo observado para que esperar si X e Y se independiente. La regla
o la relación entre el apoyo observado para que esperar si X e Y se independiente. La regla  tiene una elevación de
tiene una elevación de  .
.- El convicción de una regla se define como
 . La regla tiene una convicción de
. La regla tiene una convicción de  y puede ser interpretado como el cociente de la frecuencia prevista que X ocurre sin Y (es decir, la frecuencia que la regla hace una predicción incorrecta) si X e Y son independientes dividido por la frecuencia observada de predicciones incorrectas. En este ejemplo, el valor de convicción de 1.2 muestra que la regla sería incorrecto 20% más a menudo (1,2 veces más a menudo), si la asociación entre X e Y fue puramente azar.
y puede ser interpretado como el cociente de la frecuencia prevista que X ocurre sin Y (es decir, la frecuencia que la regla hace una predicción incorrecta) si X e Y son independientes dividido por la frecuencia observada de predicciones incorrectas. En este ejemplo, el valor de convicción de 1.2 muestra que la regla sería incorrecto 20% más a menudo (1,2 veces más a menudo), si la asociación entre X e Y fue puramente azar.
 . La regla
. La regla  y puede ser interpretado como el cociente de la frecuencia prevista que X ocurre sin Y (es decir, la frecuencia que la regla hace una predicción incorrecta) si X e Y son independientes dividido por la frecuencia observada de predicciones incorrectas. En este ejemplo, el valor de convicción de 1.2 muestra que la regla
y puede ser interpretado como el cociente de la frecuencia prevista que X ocurre sin Y (es decir, la frecuencia que la regla hace una predicción incorrecta) si X e Y son independientes dividido por la frecuencia observada de predicciones incorrectas. En este ejemplo, el valor de convicción de 1.2 muestra que la regla Proceso

 artículos. Esto se llama el
propiedad de cierre hacia abajo.
[2]
artículos. Esto se llama el
propiedad de cierre hacia abajo.
[2]
Las reglas de asociación son generalmente requeridas para satisfacer un apoyo mínimo especificado por el usuario y una confianza mínima especificada por el usuario al mismo tiempo. Generación de reglas de asociación se divide generalmente en dos pasos separados:
- En primer lugar, mínimo apoyo se aplica para encontrar todo itemsets frecuentes en una base de datos.
- En segundo lugar, estos itemsets frecuentes y la restricción mínima confianza se utilizan para formar las reglas.
Mientras que el segundo paso es sencillo, el primer paso necesita más atención.
Encontrando todos itemsets frecuentes en una base de datos es difícil puesto que implica buscar todos itemsets posibles (artículo combinaciones). El conjunto de itemsets posible es la conjunto potencia sobre y tiene tamaño 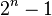 (excluyendo el conjunto vacío, que no es un conjunto de ítems válido). Aunque el tamaño de la powerset crece exponencialmente el número de artículos en , búsqueda eficiente es posible utilizando el propiedad de cierre hacia abajo de apoyo[2][4] (también llamado anti-moniticidad[5]) que garantiza que por un conjunto de ítems frecuente, todos sus subconjuntos son también frecuentes y así para un conjunto de ítems infrecuente, todos sus súper series también deben ser infrecuentes. Aprovechando esta propiedad, algoritmos eficientes (por ejemplo, Apriori[6] y Eclat[7]) puede encontrar todo itemsets frecuentes.
(excluyendo el conjunto vacío, que no es un conjunto de ítems válido). Aunque el tamaño de la powerset crece exponencialmente el número de artículos en , búsqueda eficiente es posible utilizando el propiedad de cierre hacia abajo de apoyo[2][4] (también llamado anti-moniticidad[5]) que garantiza que por un conjunto de ítems frecuente, todos sus subconjuntos son también frecuentes y así para un conjunto de ítems infrecuente, todos sus súper series también deben ser infrecuentes. Aprovechando esta propiedad, algoritmos eficientes (por ejemplo, Apriori[6] y Eclat[7]) puede encontrar todo itemsets frecuentes.
Historia
Popularizó el concepto de reglas de asociación particularmente debido al artículo 1993 de Agrawal et al.,[2] que ha adquirido más de 6.000 citas según Google Scholar, a partir de marzo de 2008, y es así uno de los artículos más citados en el campo de la minería de datos. Sin embargo, es posible que ahora se llama "reglas de asociación" es similar a lo que aparece en el documento de 1966[8] en GUHA, desarrolló un método de minería de datos generales por Petr Hájek et al.[9]
Medidas alternativas de interés
Además de las medidas de confianza, otras de interestingness para las reglas se han propuesto. Algunas medidas populares son:
- Todo-confianza[10]
- Fuerza colectiva[11]
- Convicción[12]
- Apalancamiento[13]
- Elevación (originalmente llamado interés)[14]
Puede encontrar una definición de estas medidas aquí. Varias medidas más se presentan y se comparan por Tan et al.[15] Buscando técnicas que se pueden modelar lo que el usuario conoce (y utilizar estos modelos como medidas de interés) es actualmente una tendencia activa de investigación bajo el nombre de "Interestingness subjetiva".
Asociaciones estadísticamente sonidas
Una limitación del enfoque estándar para descubrir las asociaciones es que mediante la búsqueda de un número masivo de posibles asociaciones en busca de colecciones de objetos que parecen estar asociados, hay un gran riesgo de encontrar muchas asociaciones espurias. Estas son las colecciones de elementos que co-ocurren con frecuencia inesperada en los datos, pero hacen sólo por casualidad. Por ejemplo, supongamos que estamos considerando una colección de 10.000 artículos y buscando las reglas que contiene dos elementos en el lado izquierdo y 1 punto en el lado derecho. Hay aproximadamente 1.000.000.000.000 dichas normas. Si aplicamos una prueba estadística de independencia con un nivel de significancia de 0.05 significa que hay sólo un 5% de probabilidades de aceptar una regla si no hay ninguna asociación. Si suponemos que hay no hay asociaciones, sin embargo habrá que esperar a encontrar las reglas de 50,000,000,000. Descubrimiento de asociación estadísticamente sonido[16][17] controla este riesgo, en la mayoría de los casos reduce el riesgo de encontrar cualquier asociaciones espurias a un nivel de significancia especificado por el usuario.
Algoritmos
Muchos algoritmos para generar las reglas de asociación se presentaron con el tiempo.
Algunos algoritmos conocidos son Apriori, Eclat y FP-Growth, pero ellos sólo hacen la mitad del trabajo, puesto que son algoritmos de minería itemsets frecuentes. Otro paso que debe hacerse después de generar las reglas de itemsets frecuentes encontrados en una base de datos.
Algoritmo Apriori
Apriori[6] es el algoritmo más conocido a las reglas de Asociación de la mina. Se utiliza una estrategia de búsqueda en amplitud para contar el apoyo de itemsets y utiliza una función de generación de candidatos que explota la propiedad de cierre hacia abajo del soporte.
Algoritmo de eclat
ECLAT[7] (Alt ECLAT, soportes para la transformación de clase de equivalencia) es un algoritmo de búsqueda en profundidad mediante intersección conjunto.
Algoritmo de FP-crecimiento
FP está parado para el patrón frecuente.
En el primer paso, el algoritmo cuenta la ocurrencia de los elementos (pares de atributo y valor) en el conjunto de datos y los almacena para 'tabla'. En el segundo paso, se construye la estructura de árbol FP insertando las instancias. Artículos en cada instancia debe ordenarse por orden decreciente de su frecuencia en el conjunto de datos, para que el árbol puede ser procesado rápidamente. Artículos en cada instancia que no alcancen el umbral de una cobertura mínima se descartan. Si muchos casos comparten elementos más frecuentes, FP-árbol proporciona alta compresión cerca de raíz del árbol.
Proceso recursivo de esta versión comprimida del principal conjunto de datos crece sets de objetos grandes directamente, en lugar de generar elementos de candidato y probándolas contra la base de datos. Crecimiento comienza desde el fondo de la tabla de cabecera (teniendo ramas más largas), encontrando coincidencia dada la condición de todas las instancias. Se crea nuevo árbol, con recuentos proyectadas desde el árbol original correspondiente al conjunto de instancias que están condicionadas por el atributo, con cada nodo a la suma de sus cuentas de los niños. Crecimiento recursivo termina cuando no condicionada en el atributo de los elementos individuales con umbral mínimo soporte, y procesamiento continúa en los restantes elementos de encabezado del FP-árbol original.
Una vez que ha finalizado el proceso recursivo, se han encontrado todos los conjuntos de gran artículo con una cobertura mínima, y creación de reglas de asociación comienza.[18]
Otros
AprioriDP
AprioriDP[19] utiliza Programación dinámica en el conjunto de ítems frecuentes minera. El principio de funcionamiento es eliminar la generación de candidatos como FP-árbol, pero apoyo cuenta en estructura de datos especializados en vez de árbol.
Asociación regla minería algoritmo basado en contexto
CBPNARM es el algoritmo desarrollado recientemente, que se desarrolla en 2013 a mina de reglas de asociación sobre la base de contexto. Se utiliza la variable de contexto sobre la base de que el apoyo de un conjunto de ítems se cambia en base a que las reglas están pobladas por fin al conjunto de reglas.
Nodo conjunto basado en algoritmos
ALETA,[20] PrePost [21] y PPV [22] están tres algoritmos basados en conjuntos de nodos. Usan los nodos en un codificación FP-árbol para representar a itemsets y emplear una estrategia de búsqueda en profundidad al descubrimiento itemsets frecuente mediante "intersección" de los conjuntos de nodos.
Procedimiento de GUHA ASSOC
GUHA es un método general para el análisis exploratorio de datos que tiene fundamentos teóricos en cálculos observacionales.[23]
El procedimiento de Asoc.[24] es un método GUHA que minas por las reglas de asociación generalizado uso rápido bitstrings operaciones. Las reglas de asociación minadas por este método son más generales que las salida por apriori, por ejemplo "artículos" se puede conectar tanto con la conjunción y disyuntivas y la relación entre antecedente y consecuente de la regla es no restringida al ajuste mínimo apoyo y confianza en apriori: puede usarse una combinación arbitraria de las medidas de interés compatibles.
Búsqueda de OPUS
OPUS es un algoritmo eficiente para el descubrimiento de la regla que, en contraste con la mayoría de las alternativas, no requiere monotono o monotono contra restricciones como mínimo apoyo.[25] Inicialmente usado para encontrar las reglas para una consecuente fijo[25][26] Posteriormente se ha extendido para encontrar las reglas con cualquier objeto como un consecuente.[27] La búsqueda de OPUS es la tecnología de núcleo en el popular Magnum Opus sistema de descubrimiento de asociación.
Lore
Una historia famosa sobre minería de regla de asociación es la historia de "cerveza y pañales". Una supuesta encuesta de comportamiento de los compradores de supermercado descubrió que los clientes (presumiblemente jóvenes) que comprar pañales tienden también a comprar cerveza. Esta anécdota se hizo popular como un ejemplo de reglas de asociación tan inesperado podría encontrarse de datos diarias. Hay diferentes opiniones sobre cuánto de la historia es verdadera.[28] Daniel Powers dice:[28]
En 1992, Thomas Blischok, Gerente de un retail consulting group en Teradata y su personal había preparado un análisis de canastas de mercado 1,2 millones de unos 25 Osco Drug stores. Las consultas de base de datos se desarrollaron para identificar las afinidades. El análisis "descubrió que entre 5:00 y 19:00 que los consumidores compraron cerveza y pañales". Osco gerentes no explotar la relación cerveza y pañales moviendo los productos más cerca juntos en los estantes.
Otros tipos de explotación minera de la Asociación
Reglas de Asociación de relación múltiple:: Las reglas de asociación relación múltiple (MRAR) es una nueva clase de asociación que gobierna en contraste con las reglas de asociación primitivo, simple y ni siquiera multi relacionales (que generalmente se extrajeron de múltiples bases de datos), cada elemento de regla consiste en una sola entidad sino varias relaciones. Estas relaciones indican una relación indirecta entre las entidades. Considere la siguiente MRAR donde el primer elemento consiste en tres relaciones vivir en, cerca y húmedo:: "Aquellos que vivir en un lugar que es cerca de la una ciudad con húmedo son y también el tipo de clima más joven de 20 -> su condición de salud es buena". Tales reglas de asociación son extraíbles de datos RDBMS o web semántica.[29]
Contexto basado en las reglas de asociación es una forma de gobierno de la asociación. Contexto basado en las reglas de asociación reclama mayor precisión en la minería regla Asociación teniendo en cuenta una variable de nombre variable oculta el contexto que cambia el conjunto final de las reglas de asociación dependiendo del valor de las variables de contexto. Por ejemplo, la orientación de las cestas en canasta análisis refleja un patrón extraño en los primeros días del mes.Esto podría ser debido contexto anormal es decir sueldo se dibuja en el comienzo del mes [30]
Contraste conjunto de aprendizaje es una forma de aprendizaje asociativo. Contraste establece los alumnos Utilice reglas que difieren significativamente en su distribución a través de subconjuntos.[31][32]
Clase ponderado aprendizaje es otra forma de aprendizaje asociativo en el cual peso puede asignarse a las clases para dar atención a un tema en particular de preocupación para el consumidor de los resultados de la minería de datos.
Descubrimiento del patrón de orden superior facilitar la captura de los patrones de orden superior (politeístas) o asociaciones de eventos que son intrínsecas a complejos datos del mundo real. [33]
Descubrimiento de K-óptimo patrón proporciona una alternativa al enfoque estándar para el aprendizaje de la regla de asociación que requiere que cada patrón aparecen con frecuencia en los datos.
Conjunto de ítems frecuente aproximado minera es una versión relajada de la minería del conjunto de ítems frecuentes que permite que algunos de los artículos en algunas de las filas a ser 0.[34]
Reglas de asociación generalizada taxonomía jerárquica (jerarquía de concepto)
Reglas de asociación cuantitativa datos categóricos y cuantitativos [35]
Reglas de Asociación de datos intervalo por ejemplo la partición se extendieron la edad en 5-año-incremento
Reglas de la Asociación
Minería patrón secuencial Descubre subsecuencias que son comunes a más de secuencias de minsup en una base de datos de secuencia, donde se encuentra minsup por el usuario. Una secuencia es una lista ordenada de las transacciones.[36]
Reglas secuenciales descubriendo las relaciones entre los elementos teniendo en cuenta el orden de tiempo. Generalmente se aplica sobre una base de datos de secuencia. Por ejemplo, una regla secuencial en base de datos de secuencias de transacciones del cliente puede ser que los usuarios que compraron una computadora y CD-ROMs, compró más adelante una webcam, con un dado confianza y apoyo.
Warmr se envía como parte de la suite de minería de datos ACE. Permite aprender regla de Asociación para reglas relacionales de primer orden.[37]
Véase también
- Secuencia minera
- Sistema de producción
Referencias
- ^ Piatetsky-Shapiro, Gregory (1991), Descubrimiento, análisis y presentación de las reglas fuertes, en Piatetsky-Shapiro, Gregory; y Frawley, William J.; eds., Knowledge Discovery in Databases, AAAI/MIT Press, Cambridge, MA.
- ^ a b c d e Agrawal, R.; Imieliński, T.; Swami, A. (1993). "Actas de la Conferencia Internacional ACM SIGMOD 1993 gestión de datos - SIGMOD 93". p. 207. Doi:10.1145/170035.170072. ISBN0897915925.
|Chapter =(ignoradoAyuda) - ^ Hipp, J.; Güntzer, U.; Nakhaeizadeh, G. (2000). "Algoritmos de minería de regla asociación---una encuesta general y comparación". ACM SIGKDD Explorations Newsletter 2:: 58. Doi:10.1145/360402.360421.
- ^ Tan, Pang-Ning; Michael, Steinbach; Kumar, Vipin (2005). "Capítulo 6. Análisis de asociación: algoritmos y conceptos básicos ". Introducción a la minería de datos. Addison-Wesley. ISBN0-321-32136-7.
- ^ Pei, Jian; Han, Jiawei; y Lakshmanan, Laks V. S.; Minera itemsets frecuente con restricciones convertibles, en Actas de la XVII Conferencia Internacional sobre datos ingeniería, 2 – 6 de abril de 2001, Heidelberg, Alemania, 2001, páginas 433-442
- ^ a b Agrawal, Rakesh; y Srikant, Ramakrishnan; Algoritmos rápidos para las reglas de la Asociación minera de grandes bases de datos, en la boca, Jorge B.; Jarke, Matthias; y Zaniolo, Carlo; editores, Actas de la XX Conferencia Internacional sobre Bases de datos muy grandes (VLDB), Santiago de Chile, septiembre de 1994, 487-499 páginas
- ^ a b Zaki, M. J. (2000). "Algoritmos escalables para minería de asociación". IEEE Transactions on Knowledge and Data Engineering 12 (3): 372 – 390. Doi:10.1109/69.846291.
- ^ Hájek, Petr; Havel, Ivan; Chytil, Metoděj; El método GUHA de determinación automática de hipótesis, Computación 1 (1966) 293-308
- ^ Hájek, Petr; Feglar, Tomas; Rauch, Jan; y Coufal, David; El método GUHA, preprocesamiento de datos y minería, Base de datos de soporte para aplicaciones de minería de datos, Springer, 2004, ISBN 978-3-540-22479-2
- ^ Omiecinski, Edward R.; Medidas alternativas de interés para las asociaciones mineras en bases de datos, IEEE Transactions on Knowledge and Data Engineering, 1:57-69, Ene/Feb 2003
- ^ Aggarwal, Charu C.; y Yu, Philip S.; Un nuevo marco para la generación de conjunto de ítems, en VAINAS 98, Simposio sobre principios de sistemas de base de datos, Seattle, WA, USA, 1998, páginas 18-24
- ^ Brin, Sergey; Motwani, Rajeev; Ullman, Jeffrey D.; y Tsur, Shalom; Dinámico conjunto de ítems reglas contando e implicación para los datos de la cesta de la compra, en SIGMOD 1997, actas del Congreso Internacional sobre gestión de datos (SIGMOD 1997) ACM SIGMOD, Tucson, Arizona, EEUU, mayo de 1997, págs. 255-264
- ^ Piatetsky-Shapiro, Gregory; Descubrimiento, análisis y presentación de las reglas fuertes, Knowledge Discovery in Databases, 1991, págs. 229-248
- ^ Brin, Sergey; Motwani, Rajeev; Ullman, Jeffrey D.; y Tsur, Shalom; Dinámico conjunto de ítems reglas contando e implicación para los datos de la cesta de la compra, en SIGMOD 1997, actas del Congreso Internacional sobre gestión de datos (SIGMOD 1997) ACM SIGMOD, Tucson, Arizona, EEUU, mayo de 1997, págs. 265-276
- ^ Tan, Pang-Ning; Kumar, Vipin; y Srivastava, Jaideep; Seleccionando la medida derecha objetiva para el análisis de asociación, Sistemas de información, 4:293-313, 2004
- ^ Webb, Geoffrey I. (2007); Descubriendo patrones importantes, Máquina aprendizaje 68(1), Países Bajos: Springer, pp. 1-33 acceso en línea
- ^ Gionis, Aristides; Mannila, Heikki; Mielikäinen, Taneli; y Tsaparas, Panayiotis; Evaluación de resultados de minería datos vía canje de aleatorización, ACM Transactions on Knowledge Discovery de datos (TKDD), volumen 1, número 3 (diciembre de 2007), el artículo Nº 14
- ^ Witten, Frank, Hall: Datos práctico rafadora aprender herramientas y técnicas, 3ª edición
- ^ D. Bhalodiya, K. M. Patel y C. Patel. Una manera eficiente de patrón frecuente encontrar con enfoque de programación dinámica [1]. NIRMA Universidad Conferencia Internacional sobre ingeniería, NUiCONE-2013, 28-30 de noviembre de 2013.
- ^ Z. Deng H. y S. L. Lv. Fast itemsets frecuentes usando Nodesets de explotación minera.[2]. Sistemas expertos con aplicaciones, 41(10): 4505 – 4512, 2014.
- ^ Z. H. Deng, Z. Wang,and J. Jiang. Un nuevo algoritmo para la minería rápido frecuente Itemsets usando N-listas [3]. CIENCIA Ciencias de la información de CHINA, 55 (9): 2008-2030, 2012.
- ^ Z. H. Deng y Z. Wang. Un nuevo método rápido Vertical para la minería patrones frecuentes [4]. Revista Internacional de sistemas de inteligencia computacional, 6 3: 733-744, 2010.
- ^ Rauch, Jan; Cálculos lógicos para el descubrimiento de conocimiento en bases de datos, en Actas del primer Simposio Europeo sobre principios de minería de datos y descubrimiento de conocimiento, Springer, 1997, págs. 47-57
- ^ Hájek, Petr; Havránek, Tomáš (1978). Formación de la hipótesis de mecanizado: Fundamentos matemáticos para una teoría General. Springer-Verlag. ISBN3-540-08738-9.
- ^ a b Webb, Geoffrey I. (1995); OPUS: Un eficiente algoritmo admisible para búsqueda desordenada, Revista de investigación de Inteligencia Artificial 3, Menlo Park, CA: AAAI Press, págs. 431-465 acceso en línea
- ^ Bayardo, Roberto J., Jr.; Agrawal, Rakesh; Gunopulos, Dimitrios (2000). "Minería regla constraint-based en bases de datos grandes y densos". Minería de datos y descubrimiento de conocimiento 4 (2): 217-240. Doi:10.1023 / A:1009895914772.
- ^ Webb, Geoffrey I. (2000); Búsqueda eficiente de las reglas de asociación, en Ramakrishnan, Raghu; y Stolfo, Sal; eds.; Actas de la sexta Conferencia Internacional ACM SIGKDD sobre descubrimiento de conocimiento y minería de datos (KDD-2000), Boston, MA, Nueva York, NY: la Association for Computing Machinery, pp. 99-107 acceso en línea
- ^ a b https://www.dssresources.com/newsletters/66.php
- ^ Ramezani, Reza, Mohamad Saraee y Mohammad Ali Nematbakhsh; MRAR: Minería multi relación Association Rules, Diario de la informática y de seguridad, 1, Nº 2 (2014)
- ^ Shaheen, M; Shahbaz, M; y Guergachi, A; Context Based Asociación Temporal Spatio positivos y negativos regla minería, Elsevier Knowledge-Based Systems, Jan de 2013, págs. 261-273
- ^ GI Webb y S. Butler y Newlands D. (2003). "En la detección de diferencias entre los grupos". KDD'03 Proceedings de la novena Conferencia Internacional ACM SIGKDD sobre descubrimiento de conocimiento y minería de datos.
- ^ Menzies, Tim; y Hu, Ying; Minería de datos para gente muy ocupada, IEEE Computer, octubre de 2003, págs. 18-25
- ^ Wong, Andrew K.C.; Wang, Yang (1997). "Descubrimiento del patrón de orden superior de valores discretos datos". IEEE Transactions on Knowledge and Data Engineering (TKDE):: 877-893.
- ^ Jinze Liu, Susan Paulsen, Xing Sun, Wang Wei, Andrew Nobel, J. P. (2006). Minería aproximada itemsets frecuente en presencia de ruido: algoritmo y análisis. Obtenido de https://CiteSeerX.ist.PSU.edu/viewdoc/Summary?DOI=10.1.1.62.3805
- ^ SALLEB-Aouissi, Ansaf; Vrain, Christel; Nortet, Cyril (2007). "QuantMiner: un algoritmo genético para reglas de asociación cuantitativa la explotación minera". Conferencia Internacional sobre Inteligencia Artificial (IJCAI):: 1035 – 1040.
- ^ Zaki, Mohammed J. (2001); PALA: Un algoritmo eficiente para la minería secuencias frecuentes, Machine Learning Journal, 42, págs. 31-60
- ^ https://www.ncbi.nlm.nih.gov/pubmed/11272703
Enlaces externos
Bibliografías
- Bibliografía extensa sobre las reglas de asociación por J.M. Luna
- Hahsler, Michael; Bibliografía anotada sobre las reglas de asociación
- Statsoft electrónico Statistics Textbook: Las reglas de asociación
Implementaciones
- Implementaciones de Java. Algoritmos de minería de regla de asociación
- SIPINA, un software de minería de datos libre, académico que incluye un modelo para el aprendizaje de la regla de asociación.
- KXEN, un software comercial de minería de datos
- Widget de Silverlight para demostración en directo de explotación minera de la regla de asociación utilizando el algoritmo Apriori
- RapidMiner, una suite de software libre de Java datos minera (Community Edition: GNU)
- Naranja, una suite de software de minería de datos libres, módulo orngAssoc
- Implementación de Rubí (AI4R)
- unenfoque, un paquete de reglas de Asociación minera y itemsets frecuentes con R
- Implementación de Christian Borgelt del Apriori, FP-Growth y Eclat
- Frecuente el conjunto de ítems minería implementaciones repositorio (FIMI)
- Patrón frecuente de minería implementaciones de Bart Goethals
- Weka, una colección de algoritmos de aprendizaje máquina para las tareas de minería de datos escritos en Java
- KNIME un flujo de trabajo de código abierto orientado a la plataforma de procesamiento y análisis de datos
- Zaki, Mohammed J.; Software de minería de datos
- Magnum Opus, un sistema para el descubrimiento de asociación estadísticamente sonido
- Minero de lISp, las minas de las reglas de asociación (GUHA) generalizadas (usos bitstrings, no algoritmo apriori)
- Ferda cartográfico, una plataforma de explotación minera extensible datos visuales, implementa procedimientos GUHA ASSOC y dispone de minería de datos multirelational
- STATISTICA, software de estadísticas comerciales con un módulo de reglas de asociación
- SPMF, una plataforma de minería de datos de código abierto ofreciendo más de 48 algoritmos para la Asociación regla minería, explotación minera del conjunto de ítems y minería patrón secuencial. Incluye un simple código java y la interfaz de usuario se distribuye bajo la licencia GPL.
- ARtool, Regla de asociación GPL Java minería aplicación con interfaz gráfica, ofrece implementaciones de varios algoritmos para el descubrimiento de patrones frecuentes y extracción de las reglas de asociación (incluye Apriori y FPgrowth)
- EasyMiner, un sistema de extracción de regla asociación basada en web para la minería interactivo. Demo gratuita. Basado en Minero de lISp