Cuadrícula de datos
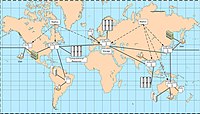
A cuadrícula de datos es un arquitectura o conjunto de servicios que da a individuos o grupos de usuarios la posibilidad de acceder, modificar y transferir cantidades extremadamente grandes de geográficamente distribuidos datos para fines de investigación.[1] Rejillas de datos que sea posible a través de una serie de middleware aplicaciones y servicios que reunir datos y recursos de múltiples Dominios administrativos y luego presentarla a los usuarios a petición. Los datos en una cuadrícula de datos pueden estar ubicados en un sitio único o múltiples sitios donde cada sitio puede ser su propio dominio administrativo regido por un conjunto de restricciones de seguridad en cuanto a quién puede acceder a los datos.[2] Asimismo, varios réplicas de los datos pueden ser distribuidos a través de la red fuera de su dominio administrativo original y las restricciones de seguridad colocadas en los datos originales para que puedan acceder a ella deben aplicarse igualmente a las réplicas.[3] Específicamente desarrollados datos middleware grid es lo que encarga de la integración entre los usuarios y los datos que se solicitan mediante el control de acceso y puesta a disposición tan eficientemente como sea posible. El diagrama a la derecha muestra una vista de alto nivel de una cuadrícula de datos.
Contenido
- 1 Middleware
- 1.1 Espacio de nombres universal
- 1.2 Servicio de transporte de datos
- 1.3 Servicio de acceso a datos
- 1.4 Servicio de replicación de datos
- 1.4.1 Estrategia de actualización de replicación
- 1.4.2 Estrategia de colocación de replicación
- 1.4.2.1 Replicación dinámica
- 1.4.2.2 Replicación adaptativa
- 1.4.2.3 Feria-cuota de replicación
- 1.4.2.4 Otra réplica
- 1.5 Tareas de programación y asignación de recursos
- 1.6 Sistema de gestión de recursos (RMS)
- 1.6.1 Capacidades funcionales RMS
- 2 Topología
- 3 Historia
- 4 Notas
- 5 Referencias
- 6 Lectura adicional
Middleware
Middleware proporciona todos los servicios y aplicaciones necesarias para una gestión eficiente de conjuntos de datos y archivos dentro de la cuadrícula de datos mientras que proporciona a los usuarios un acceso rápido a los archivos y bases de datos.[4] Hay una serie de conceptos y herramientas que deben estar disponibles para hacer una cuadrícula de datos operacionalmente viable. Sin embargo, al mismo tiempo no todas las redes de datos requieren las mismas capacidades y servicios debido a las diferencias en los requerimientos de acceso, seguridad y localización de recursos en comparación con los usuarios. En cualquier caso, la mayoría de las redes de datos tendrá similares servicios middleware que prevén un universal espacio de nombres, transporte de datos servicio, servicio de acceso a datos, replicación de datos y servicio de gestión de recursos. Tomados en conjunto, son clave para las capacidades funcionales rejillas de datos.
Espacio de nombres universal
Desde fuentes de datos dentro de la cuadrícula de datos constará de los datos de múltiples sistemas separados y redes uso de archivo diferente Convenciones de nomenclatura, que sería difícil para un usuario localizar datos dentro de la cuadrícula de datos y saber recuperaron lo que necesitaban basada únicamente en nombres de archivo físico existentes (PFNs). Un espacio de nombres universales o unificado hace posible crear archivo lógico nombres (LFNs) que se pueden hacer referencia dentro de la cuadrícula de datos que se asignan a los PFNs.[5] Cuando un LFN es solicitado o consultar, todas coincidentes PFNs vuelven a incluyen posibles réplicas de los datos solicitados. El usuario final puede elegir luego de los resultados devueltos la réplica más apropiada utilizar. Este servicio se proporciona generalmente como parte de un sistema de gestión conocido como un Broker de recursos de almacenamiento (SRB).[6] Información acerca de las ubicaciones de los archivos y las asignaciones entre los LFNs y los PFNs puede almacenarse en un metadatos o catálogo de réplica.[7] El catálogo de réplica contendría información sobre LFNs que se asignan a múltiples réplicas PFNs.
Servicio de transporte de datos
Otro servicio de middleware es la de proveer para el transporte de datos o transferencia de datos. Transporte de datos abarcará varias funciones que no se limitan sólo a la transferencia de bits, para incluir artículos tales como tolerancia a fallos y acceso a datos.[8] Tolerancia a fallos puede lograrse en una cuadrícula de datos, proporcionando mecanismos que asegura la transferencia de datos se reanudará después de cada interrupción hasta todos los datos solicitados se recibe.[9] Hay varios posibles métodos que podrían utilizarse para incluir empezar desde el principio de los datos de la transmisión entera para reanudar desde donde se interrumpió la transferencia. Por ejemplo, GridFTP proporciona para tolerancia a fallas mediante el envío de datos desde el último byte reconocido sin iniciar a la transferencia completa desde el principio.
El servicio de transporte de datos también prevé el acceso de bajo nivel y las conexiones entre anfitriones para transferencia de archivos.[10] El servicio de transporte de datos puede utilizar cualquier número de modos de realizar la transferencia para incluir la transferencia de datos paralela donde se utilizan dos o más flujos de datos sobre los mismos canal o la transferencia de datos particionados donde dos o más vástagos acceder diferentes bloques del archivo de transferencia simultánea también usando las capacidades incorporadas subyacentes del hardware de red o específicamente desarrollado protocolos para soportar velocidades de transferencia más rápidas.[11] El servicio de transporte de datos puede incluir opcionalmente un superposición de red función para facilitar el enrutamiento y transferencia de datos así como archivo ENTRADA-SALIDA funciones que permiten a los usuarios ver archivos remotos como si fueran locales a su sistema. El servicio de transporte de datos oculta la complejidad del acceso y la transferencia entre los distintos sistemas para el usuario y aparece como un origen de datos unificada.
Servicio de acceso a datos
Acceso a datos servicios trabajo mano a mano con el servicio de transferencia de datos para proporcionar seguridad, controles de acceso y gestión de cualquier transferencia de datos dentro de la cuadrícula de datos.[12] Los servicios de seguridad proporcionan mecanismos para la autenticación de los usuarios para asegurarse de que estén debidamente identificados. Formas comunes de seguridad para la autenticación pueden incluir el uso de contraseñas o Kerberos (protocolo). Servicios de autorización son los mecanismos que controlan lo que es capaz de acceder después de ser identificados a través de la autenticación del usuario. Formas comunes de mecanismos de autorización pueden ser tan simples como permisos de archivo. Sin embargo, la necesidad de acceso controlado más estricta a los datos se realiza utilizando Listas de Control de acceso (ACL), Role-Based Access Control (RBAC) y controles de autorización basado en la tarea (TBAC).[13] Estos tipos de controles pueden utilizarse para proporcionar acceso granular a los archivos que incluyen límites a los tiempos de acceso, duración del acceso a los controles granulares que determinan los archivos que se puede leer o escrito. El servicio de acceso a datos finales que puede estar presente para proteger la confidencialidad del transporte de datos está cifrado.[14] La forma más común de cifrado para esta tarea ha sido el uso de SSL mientras que en el transporte. Mientras que todos estos servicios de acceso a operan dentro de la cuadrícula de datos, servicios de acceso dentro de los diferentes dominios administrativos que albergan los conjuntos de datos todavía permanecerá en lugar de hacer cumplir las reglas de acceso. Los servicios de acceso a la red datos deben ser en consonancia con los dominios administrativos servicios de acceso para que funcione.
Servicio de replicación de datos
Para satisfacer las necesidades de escalabilidad, rápido acceso y colaboración del usuario, la mayoría de las redes de datos soportan replicación de bases de datos a puntos dentro de la arquitectura de almacenamiento distribuido.[15] El uso de réplicas permite que varios usuarios un acceso más rápido a los conjuntos de datos y la preservación del ancho de banda desde réplicas a menudo se pueden colocar estratégicamente cerca de o dentro de los sitios donde los usuarios necesitan. Sin embargo, replicación de bases de datos y creación de réplicas está limitados por la disponibilidad de almacenamiento dentro de sitios y de ancho de banda entre sitios. La replicación y la creación de conjuntos de datos de réplica es controlada por un sistema de gestión de réplica. El sistema de gestión de réplica determina el usuario necesita para réplicas basadas en las peticiones de entrada y crea basado en la disponibilidad de ancho de banda y almacenamiento.[16] Todas las réplicas son luego catalogadas o añadidas a un directorio basado en la cuadrícula de datos en cuanto a su ubicación para consulta de los usuarios. Para realizar las tareas emprendidas por el sistema de administración de réplica, necesita ser capaz de manejar la infraestructura de almacenamiento subyacente. El sistema de gestión de datos también garantizará que la actualización oportuna de cambios a las réplicas se propaga a todos los nodos.
Estrategia de actualización de replicación
Hay un número de formas en que el sistema de administración de replicación puede manejar las actualizaciones de réplicas. Las actualizaciones pueden ser diseñadas alrededor de un modelo centralizado donde una sola maestra réplica actualiza todos los demás, o un modelo descentralizado, donde todos los participantes actualización mutuamente.[17] La topología de la colocación de nodo también puede influir en las actualizaciones de réplicas. Si se utiliza una topología de jerarquía actualizaciones fluiría en un árbol como la estructura a través de recorridos específicos. En una topología plana es completamente un asunto de las relaciones entre iguales entre nodos en cuanto a cómo ocurren las actualizaciones. En una topología híbrida consiste en topologías tanto plana y jerarquía de las actualizaciones pueden tener lugar a través de rutas específicas y entre pares.
Estrategia de colocación de replicación
Hay un número de formas en que el sistema de administración de replicación puede manejar la creación y colocación de réplicas para servir mejor a la comunidad de usuarios. Si la arquitectura de almacenamiento admite la colocación de la réplica con suficientes sitios de almacenamiento, entonces se convierte en un asunto de las necesidades de los usuarios que accedan a los conjuntos de datos y una estrategia para la colocación de las réplicas.[18] Ha habido numerosas estrategias propuesto y probado en cómo manejar mejor la colocación de la réplica de conjuntos de datos dentro de la cuadrícula de datos para satisfacer los requerimientos del usuario. No hay no una estrategia universal que se adapta a todas las exigencias de los mejores. Se trata del tipo de datos grid y usuario los requisitos comunitarios de acceso que va a determinar la mejor estrategia a utilizar. Las réplicas se pueden crear incluso donde los archivos son encriptados para garantizar la confidencialidad que sería útil en una investigación sobre proyecto archivos médicos.[19] La siguiente sección contiene varias estrategias para la colocación de la réplica.
Replicación dinámica
Replicación dinámica es una aproximación a la colocación de réplicas basado en la popularidad de los datos.[20] El método ha sido diseñado alrededor de un modelo jerárquico de replicación. El sistema de gestión de datos mantiene un registro de almacenamiento disponible en todos los nodos. También realiza un seguimiento de las solicitudes (golpes) que solicitan los clientes datos (usuarios) en un sitio. Cuando el número de golpes para un conjunto específico de datos excede el umbral de replicación que provoca la creación de una réplica en el servidor que los servicios directamente el cliente del usuario. Si el directo servicio servidor conocido como un padre no tiene espacio suficiente, entonces padre el padre de tu en la jerarquía es el objetivo de recibir una réplica y así sucesivamente hasta la cadena hasta que se agote. El algoritmo de sistema de gestión de datos también permite la supresión dinámica de réplicas que tienen un valor de acceso nulo o un valor inferior a la frecuencia de los datos a ser almacenados para liberar espacio. Esto mejora el rendimiento del sistema en términos de tiempo de respuesta, número de réplicas y ayuda a equilibrar la carga a través de la cuadrícula de datos. Este método también puede utilizar algoritmos dinámicos que determinan si el costo de crear la réplica es realmente vale la pena los beneficios esperados dados la ubicación.[21]
Replicación adaptativa
Este método de replicación como la replicación dinámica ha sido diseñado alrededor de un modelo jerárquico replicación encontrado en la mayoría de las redes de datos. Trabaja en un algoritmo similar a la replicación dinámica con las solicitudes de acceso de archivo siendo un factor primordial para determinar qué archivos deben replicarse. Una diferencia clave, sin embargo, es el número y frecuencia de las creaciones de réplica se rayó a un umbral dinámico que se calcula basado en petición tasas de llegada de clientes durante un período de tiempo.[22] Si el número de solicitudes en promedio supera el umbral anterior y muestra una tendencia al alza, y capacidad para crear réplicas más indican que las tasas de utilización de almacenamiento, pueden crearse más réplicas. Como replicación dinámica, con la eliminación de réplicas que tienen un umbral más bajo que no se crearon en el intervalo de réplica actual puede retirarse para hacer espacio para las nuevas réplicas.
Como los métodos de replicación adaptativa y dinámico antes, Feria-compartir la replicación se basa en un modelo jerárquico de replicación. También, como antes, la popularidad de los archivos de los dos juega un papel clave en la determinación de los archivos que se replicará. La diferencia con este método es que la colocación de las réplicas se basa en acceso carga y almacenamiento de carga de servidores de candidato.[23] Un servidor candidato tenga suficiente espacio de almacenamiento, pero ser servicio a muchos clientes para tener acceso a los archivos almacenados. Colocar una réplica de este candidato puede degradar el rendimiento para todos los clientes tener acceso a este servidor de candidato. Por lo tanto, la colocación de las réplicas con este método se realiza mediante la evaluación de cada nodo de candidato para la carga de acceso encontrar un nodo adecuado para la colocación de la réplica. Si todos los nodos del candidato son clasificados equivalente para el acceso de carga, ninguno o menos accesible que el otro, entonces el nodo del candidato con la menor carga de almacenamiento será el elegido para albergar las réplicas. Métodos similares a la otra describen métodos se utilizan para quitar sin usar la replicación o menor solicitado repeticiones si es necesario. Las réplicas que se retiran podrían ser movidas a un nodo principal para su posterior reutilización debe vuelven populares.
Otra réplica
Las anteriores estrategias de tres réplica o tres de muchas estrategias de replicación posibles que pueden utilizarse para colocar réplicas dentro de la cuadrícula de datos donde mejorarán rendimiento y acceso. A continuación se presentan algunos otros que se han propuesto y probado junto con las estrategias de replicación se describió anteriormente.[24]
- Estática – utiliza un conjunto fijo de nodos sin cambios dinámicos en los archivos se repliquen.
- Mejor cliente – Cada nodo registra el número de solicitudes por archivo recibido durante un intervalo de tiempo preestablecido; Si el número de solicitud supera el umbral establecido para un archivo se crea una réplica en el mejor cliente, que solicitó el archivo más; réplicas obsoletos se retiran basado en otro algoritmo.
- Conexión en cascada – Se utiliza en una estructura jerárquica nodo donde solicitudes por archivo recibido durante un intervalo de tiempo preestablecido se compara contra un umbral. Si se supera el umbral de una réplica se crea en el primer nivel hacia abajo de la raíz, si se supera el umbral de otra vez una réplica se añade al siguiente nivel hacia abajo y así sucesivamente como un efecto de cascada hasta una réplica se coloca en el propio cliente.
- Almacenamiento en caché de llano – Si el cliente solicita un archivo se almacena como una copia en el cliente.
- Almacenamiento en caché y en cascada – Combina dos estrategias de almacenamiento en caché y en cascada.
- Rápida propagación – También se utiliza en una estructura jerárquica nodo esta estrategia rellena automáticamente todos los nodos en la ruta de acceso del cliente que solicita un archivo.
Tareas de programación y asignación de recursos
Características de los sistemas de red de datos tales como la gran escala y la heterogeneidad requieren métodos específicos de las tareas de programación y asignación de recursos. Para resolver el problema, la mayoría de sistemas usan extendidos métodos clásicos de programación.[25] Otros invitan fundamentalmente diferentes métodos basados en incentivos para los nodos autónomos, como dinero virtual o la reputación de un nodo. Otra especificidad de las redes de datos, dinámica, consiste en el proceso continuo de conexión y desconexión de nodos y el desequilibrio de carga local durante la ejecución de tareas. Eso puede hacer obsoletos o no óptimos resultados iniciales de asignación de recursos para una tarea. Como resultado, gran parte de las cuadrículas de datos utilizan técnicas de adaptación de tiempo de ejecución que permiten los sistemas para reflejar los cambios dinámicos: balancear la carga, reemplazar los nodos de desconexión, utilizar el beneficio de nodos conectados nuevamente, recuperar una ejecución de la tarea después de fallas.
Sistema de gestión de recursos (RMS)
El sistema de gestión de recursos representa la funcionalidad básica de la cuadrícula de datos. Es el corazón del sistema que administra todas las acciones relacionadas con los recursos de almacenamiento de información. En algunas redes de datos puede ser necesario crear una arquitectura de RMS FED debido a las diferentes políticas administrativas y una diversidad de posibilidades que se encuentran dentro de la cuadrícula de datos en lugar de usando una sola RMS. En tal caso las RMSs en la Federación empleará una arquitectura que permite la interoperabilidad basada en un acuerdo sobre el conjunto de protocolos para las acciones relacionadas con los recursos de almacenamiento de información.[26]
Capacidades funcionales RMS
- Cumplimiento de las solicitudes de usuario y aplicación de recursos de datos basados en el tipo de solicitud y políticas; RMS será capaz de soportar múltiples políticas y múltiples solicitudes concurrentemente
- Programación, sincronización y creación de réplicas
- Aplicación de la política y la seguridad dentro de los recursos de red de datos que incluyen autenticación, autorización y acceso
- Sistemas de apoyo con diferentes políticas administrativas para operar entre preservando la autonomía de sitio
- Apoyar la calidad de servicio (QoS) cuando solicitado if característica disponible
- Cumplir los requisitos del sistema culpa tolerancia y estabilidad
- Gestionar los recursos, es decir, almacenamiento en disco, banda de ancho y todos los demás recursos que interactúan directamente o como parte de la cuadrícula de datos
- Administrar fideicomisos con respecto a los recursos en dominios administrativos, algunos dominios pueden colocar restricciones adicionales sobre cómo participan adaptación que requieren de la RMS o Federación.
- Apoya la adaptabilidad, la extensibilidad y escalabilidad en lo referente a la cuadrícula de datos.
Topología

Rejillas de datos han sido diseñadas para satisfacer las necesidades de la comunidad científica con varias topologías en mente. A la derecha son cuatro diagramas de diversas tipologías que se han utilizado en las redes de datos.[27] Cada topología tiene un propósito específico en mente para donde lo mejor se utilizará. Además cada una de estas topologías se explica a continuación.
Topología de Federación es la opción para las instituciones que desean compartir datos ya existentes sistemas. Permite el control de cada institución sobre sus datos. Cuando una institución con datos de solicitudes de autorización de otra institución depende de la institución que recibe la solicitud para determinar si los datos se irán a la institución solicitante. La Federación puede integrarse libremente entre las instituciones, estrechamente integradas o una combinación de ambos.
Topología monádico tiene un repositorio central que todo recogido datos alimenta. El repositorio central responde a todas las consultas de datos. Hay no hay réplicas en esta topología en comparación con otros. Datos sólo es accesible desde el repositorio central que podría ser a través de un portal web. Un proyecto que utiliza esta topología de red de datos es el Network for Earthquake Engineering Simulation (NEES) en los Estados Unidos.[28] Esto funciona bien cuando todos los accesos a los datos sea local o en una sola región con conectividad de alta velocidad.
Topología jerárquica se presta colaboración donde hay una sola fuente para los datos y tiene que ser distribuido en varias ubicaciones alrededor del mundo. Uno de esos proyectos que se beneficiará de esta topología sería CERN que se ejecuta la Gran Colisionador de Hadrones genera enormes cantidades de datos. Estos datos se encuentra en una fuente y tiene que ser distribuido alrededor del mundo a las organizaciones que están colaborando en el proyecto.
Topología híbrida es simplemente una configuración que contiene una arquitectura consiste en cualquier combinación de las topologías anteriores mencionadas. Se utiliza principalmente en situaciones donde investigadores trabajando en proyectos quieren compartir sus resultados de investigación adicional haciéndola disponible para la colaboración.
Historia
La necesidad de redes de datos primero fue reconocida por el comunidad científica con respecto a modelado climático, donde terabyte y petabyte tamaño conjuntos de datos estaban convirtiendo en la norma para el transporte entre sitios.[29] Requisitos de investigación más recientes para redes de datos han sido expulsados por la Gran Colisionador de Hadrones (LHC) en CERN, la Observatorio de ondas gravitacionales de interferómetro láser (LIGO)y el Sloan Digital Sky Survey (SDSS). Estos ejemplos de instrumentos científicos producen grandes cantidades de datos que tienen que ser accesibles por grandes grupos de investigadores dispersos geográficamente.[30][31] Otros usos para las rejillas de datos involucran a los gobiernos, hospitales, escuelas y negocios donde los esfuerzos realizan para mejorar servicios y reducir los costos al proporcionar acceso a los sistemas de datos dispersos y separados mediante el uso de redes de datos.[32]
Desde sus primeros inicios, el concepto de una cuadrícula de datos para apoyar a la comunidad científica fue pensado como una extensión especializada de la "red" que sí mismo primero fue concebida como un modo de enlazar computadoras estupendas en meta-computadoras.[33] Sin embargo, corta que vivía y la red evolucionada hacia lo que significa la capacidad de conectar computadoras en cualquier lugar de la web para tener acceso a los archivos deseados y recursos, similares a la electricidad de manera se entrega sobre una cuadrícula conectando simplemente en un dispositivo. El dispositivo obtiene electricidad a través de su conexión y la conexión no se limita a una salida específica. De esto la cuadrícula de datos fue propuesta como una arquitectura integradora que sería capaz de suministrar los recursos para los cómputos distribuidos. También podrá atender numerosos a miles de consultas al mismo tiempo mientras que entregan gigabytes a terabytes de datos para cada consulta. La cuadrícula de datos incluiría su propia infraestructura de administración capaz de gestionar todos los aspectos del rendimiento de las redes de datos y operación a través de múltiples redes de área extensa mientras se trabaja dentro del marco existente, conocido como la web.[34]
La cuadrícula de datos también se ha definido más recientemente en términos de usabilidad; ¿Qué una cuadrícula de datos deben poder hacer en orden para que sea útil a la comunidad científica. Los defensores de esta teoría llegaron a varios criterios.[35] Uno, los usuarios deben ser capaces de buscar y descubrir recursos aplicables dentro de la cuadrícula de datos de entre sus muchos conjuntos de datos. Dos, los usuarios deben ser capaces de localizar conjuntos de datos dentro de la cuadrícula de datos que son los más adecuados para sus necesidades de entre las numerosas réplicas. Tres, los usuarios deben ser capaces de transferir y mover grandes conjuntos de datos entre puntos en un período corto de tiempo. Cuatro, la cuadrícula de datos debe proporcionar un medio para gestionar múltiples copias de bases de datos dentro de la cuadrícula de datos. Y finalmente, la cuadrícula de datos debería ofrecer una seguridad con controles de acceso de usuario dentro de la cuadrícula de datos, es decir, que los usuarios pueden acceder a los datos.
La cuadrícula de datos es una tecnología en constante evolución que continúa para cambiar y crecer para satisfacer las necesidades de una comunidad creciente. Uno de los primeros programas comenzados a convertir en realidad las redes de datos fue financiado por el Defense Advanced Research Projects Agency (DARPA) en 1997 en el Universidad de Chicago.[36] Esta investigación generada por DARPA ha seguido el camino a la creación de herramientas de código abierto que hacen posible las redes de datos. Como nuevos requisitos para datos rejillas surgen proyectos como el Globus Toolkit emergen o ampliar para cubrir la brecha. Rejillas de datos junto con el "Grid" continuará evolucionando.
Notas
- ^ Allcock, Bill; Chervenak, Ann; Foster, Ian; herramientas de cuadrícula de datos et al.: permitiendo ciencia en grande distribuye datos
- ^ Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri. Una taxonomía de las redes de datos para compartir - gestión y procesamiento p.37 de datos distribuidos
- ^ Shorfuzzaman, Mohammad; Graham, Peter; Eskicioglu, Rasit. Colocación de la réplica adaptable en cuadrículas de datos jerárquicos. p.15
- ^ Padala, Pradeep. Una encuesta de datos middleware para rejilla sistemas p.1
- ^ Padala, Pradeep. Una encuesta de datos middleware para sistemas Grid
- ^ Arcot, Rajasekar; WAN, Michael; Moore, Reagan; Schroeder, Wayne; Kremenek. Agente de almacenamiento recursos – gestión de datos distribuidos en una cuadrícula
- ^ Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri. Una taxonomía de las redes de datos para compartir - gestión y procesamiento p.11 de datos distribuidos
- ^ Coetzee, Serena. Modelo de referencia para un enfoque de rejilla de datos a los datos de la dirección de una dinámica p.16 SDI
- ^ Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri. Una taxonomía de las redes de datos para compartir - gestión y procesamiento p.21 de datos distribuidos
- ^ Allcock, Bill; Foster, Ian; Nefedova, Veronika; Chervenak, Ann; Deelman, Ewa; Kesselman, Carl. Alto rendimiento acceso remoto a los datos de simulación del clima: un problema de desafío para tecnologías de red de datos.
- ^ Izmailov, Rauf; Ganguly, Samrat; Tu, Nan. Replicación de archivos rápido paralelo de datos red p.2
- ^ Raman, Vijayshankar; Narang, Inderpal; Crone, chris; Hass, Laura; Malaika, Susan. Servicios de acceso a datos y procesamiento de datos en redes
- ^ Thomas, R. K. y controles de autorización basada en tareas Sandhu R. S. (tbac): una familia de modelos de gestión activa y orientada a la empresa autorización
- ^ Sreelatha, Malempati. Enfoque basado en la red para la confidencialidad de los datos. p.1
- ^ Chervenak, Ann; Schuler, Robert; Kesselman, Carl; Koranda, Scott; Moe, Brian. Replicación de datos de área amplia para colaboraciones científicas
- ^ Lamehamedi, Houda; Szymanski, Boleslaw; Shentu, Zujun; Deelman, Ewa. Estrategias de replicación de datos en entornos de red
- ^ Lamehamedi, Houda; Szymanski, Boleslaw; Shentu, Zujun; Deelman, Ewa. Estrategias de replicación de datos en entornos de red
- ^ Padala, Pradeep. Una encuesta de datos middleware para sistemas Grid
- ^ Microencapsulados, G. y Rekha, Shashi D.. Replicación de objetos de datos protegidos en Kaynes de cuadrícula de datos
- ^ Belalem, Ghalem y Meroufel, Bakhta. Manejo y colocación de réplicas en una cuadrícula de datos jerárquicos
- ^ Lamehamedi, Houda; Szymanski, Boleslaw; Shentu, Zujun; Deelman, Ewa. Estrategias de replicación de datos en entornos de red
- ^ Shorfuzzaman, Mohammad; Graham, Peter; Eskicioglu, Rasit. Colocación de la réplica adaptable en cuadrículas de datos jerárquicos
- ^ Rasool, Qaisar; Li Jianzhong; Oreku, George S.; Munir, Ehsan Ullah. Feria-cuota de replicación en la cuadrícula de datos
- ^ Ranganathan, Kavitha y Foster, Ian. Identificando las estrategias de replicación dinámica para una cuadrícula de datos de alto rendimiento
- ^ Epimakhov, Igor; Hameurlain, Abdelkader; Dillon, Tharam; Morvan, Franck. Programación de métodos de optimización de consultas en sistemas de red de datos de recursos
- ^ Kräuter, Klaus; Buyya, Rajkumar; Maheswaran, Muthucumaru. Una encuesta de sistemas de gestión de recursos de red para computación distribuida y taxonomía
- ^ Zhu, Lichun. Administración de metadatos en Federación de base de datos de red
- ^ Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri. Una taxonomía de las redes de datos para datos distribuidos compartir - gestión y procesamiento p.16
- ^ Allcock, Bill; Foster, Ian; Nefedova, Veronika; Chervenak, Ann; Deelman, Ewa; Kesselman, Carl. Alto rendimiento acceso remoto a los datos de simulación del clima: un problema de desafío para tecnologías de red de datos.
- ^ Allcock, Bill; Chervenak, Ann; Foster, Ian; p.571 et al.
- ^ Tierney, problemas de performance de Brian L. Data redes y datos de red. p.7
- ^ Thibodeau, P. gobiernos planificar proyectos de cuadrícula de datos
- ^ Heingartner, douglas. La red: la próxima generación internet
- ^ Heingartner, douglas. La red: la próxima generación internet
- ^ Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri. Una taxonomía de las redes de datos para compartir - gestión y procesamiento p.1 de datos distribuidos
- ^ Globus. Sobre globus toolkit
Referencias
- Allcock, Bill; Chervenak, Ann; Foster, Ian; Kesselman, Carl; Livny, Miron (2005). "Herramientas de cuadrícula de datos: permitiendo ciencia en grande distribuye datos". Journal of Physics: ciclo de conferencias (Instituto de física de la publicación) 16:: 571 – 575. Doi:10.1088/1742-6596/16/1/079. 15 de abril, 2012.
- Allcock, Bill; Foster, Ian; Nefedova, Veronika l; Chervenak, Ann; Deelman, Ewa; Kesselman, Carl; Lee, Jason; SIM, Alex; Shoshani, Arie; Drach, Bob; Williams, decano (2001). "Alto rendimiento acceso remoto a los datos de simulación del clima: un problema de desafío para tecnologías de red de datos". ACM Press. OAI: 10.1.1.64.6603.
- Arcot, Rajasekar; WAN, Michael; Moore, Reagan; Schroeder, Wayne; Kremenek, George. "Intermediario de recursos almacenamiento – gestión de datos distribuidos en una cuadrícula". 28 de abril, 2012.
- Belalem, Ghalem; Meroufel, Bakhta (2011). "Gestión y colocación de réplicas en una cuadrícula de datos jerárquicos". Revista Internacional de sistemas distribuidos y paralelos (IJDPS) 2 (6): 23 – 30. Doi:10.5121/ijdps.2011.2603. 28 de abril, 2012.
- Chervenak, A.; Foster, I.; Kesselman, C.; Salisbury, C.; Tuecke, S. (2001). "La cuadrícula de datos: hacia una arquitectura para la gestión distribuida y análisis de grandes conjuntos de datos científicos". Revista de la red y aplicaciones informáticas 23:: 187-200. Doi:10.1006/jnca.2000.0110. 11 de abril, 2012.
- Chervenak, Ann; Schuler, Robert; Kesselman, Carl; Koranda, Scott; Moe, Brian (14 de noviembre de 2005). "Replicación de datos de área amplia para colaboraciones científicas". IEEE. 25 de abril, 2012.
- Coetzee, Serena (2012). "Modelo de referencia para un enfoque de red de datos a los datos de la dirección de una dinámica SDI". Geoinformatica 16 (1): 111 – 129. Doi:10.1007/s10707-011-0129-4. 28 de abril, 2012.
- Epimakhov, Igor; Hameurlain, Abdelkader; Dillon, Tharam; Morvan, Franck (2011). "Avances en bases de datos e información de sistemas. XV Conferencia Internacional, ADBIS 2011". Viena, Austria: Springer Berlín Heidelberg. págs. 185-199. Doi:10.1007/978-3-642-23737-9_14. 20 de septiembre, 2011.
|Chapter =(ignoradoAyuda)
- Globus (2012). "Sobre el globus toolkit". Globus. 27 de mayo, 2012.
- Heingartner, Douglas (08 de marzo de 2001). "La red: la próxima generación Internet". Atado con alambre. 13 de mayo, 2012.
- Izmailov, Rauf; Ganguly, Samrat; Tu, Nan (2004). "Replicación de archivos rápido paralelo en la cuadrícula de datos". 10 de mayo, 2012.
- Microencapsulados, Aruna G.; Rekha, D. Shashi (2012). "Replicación de objetos de datos en una cuadrícula de datos protegidos". Revista Internacional de seguridad de la red y sus aplicaciones (IJNSA) 4 (1): 29 – 41. Doi:10.5121/ijnsa.2012.4103. ISSN0975-2307. 1 de abril 2012.
- Kräuter, Klaus; Buyya, Rajkumar; Maheswaran, Muthucumaru (2002). "Una taxonomía y el estudio de sistemas de gestión de recursos de red para la informática distribuida". Software práctica y experiencia (SPE) 32 (2): 135 – 164. Doi:10.1002/SPE.432. OAI: 10.1.1.38.2122.
- Lamehamedi, Houda; Szymanski, Boleslaw; Shentu, Zujun; Deelman, Ewa (2002). "Fifth International Conference on algoritmos y arquitecturas para procesamiento en paralelo (ICA3PP'02)". Prensa. págs. 378-383. OAI: 10.1.1.11.5473.
|Chapter =(ignoradoAyuda)
- Padala, Pradeep. "Una encuesta de datos middleware para sistemas Grid". OAI: 10.1.1.114.1901.
- Raman, Vijayshankar; Narang, Inderpal; Crone, Chris; Hass, Laura; Malaika, Susan (09 de febrero de 2003). "Servicios de acceso a datos y procesamiento de datos en redes". 10 de mayo, 2012.
- Ranganathan, Kavitha; Foster, Ian (2001). "En Proc. de la red internacional de taller de computación". págs. 75-86. Doi:10.1007/3-540-45644-9_8. OAI: 10.1.1.20.6836.
|Chapter =(ignoradoAyuda)
- Rasool, Qaisar; Li Jianzhong; Oreku, George S.; Munir, Ehsan Ullah (2008). "Fair-share replicación en cuadrícula de datos". Revista de tecnología de información 7 (5): 776 – 782. Doi:10.3923/ITJ.2008.776.782. 27 de abril, 2012.
- Shorfuzzaman, Mohammad; Graham, Peter; Eskicioglu, Rasit (2010). "Colocación de la réplica adaptable en cuadrículas de datos jerárquicos". Journal of Physics: ciclo de conferencias (IOP Publishing Ltd) 256 (1): 1 – 18. Doi:10.1088/1742-6596/256/1/012020. 15 de abril, 2012.
- Sreelatha, Malempati (2011). "Enfoque para la confidencialidad de los datos basado en grid". Revista Internacional de aplicaciones informáticas 25 (9): 1 – 5. Doi:10.5120/3063-4186. ISSN0975-8887. 28 de abril, 2012.
- Thibodeau, P. (30 de mayo de 2005). "Los gobiernos plan de proyectos de la red de datos". Computerworld (Estados Unidos: Computerworld) 39 (42): 14. ISSN0010-4841. 28 de abril, 2012.
- Thomas, K. R.; Sandhu, R. S. (1997). "Controles de autorización basada en tareas (tbac): una familia de modelos de gestión activa y orientada a la empresa autorización". 28 de abril, 2012.
- Tierney, Brian L. (2000). "Las redes de datos y problemas de rendimiento de red de datos". 28 de abril, 2012.
- Venugopal, Srikumar; Buyya, Rajkumar; Ramamohanarao, Kotagiri (2006). "Una taxonomía de las redes de datos para el intercambio de datos distribuidos, gestión y tramitación". ACM Computing Surveys (Csur del) (Nueva York: Association for Computing Machinery) 38 (1): 1 – 60. 10 de abril, 2012.
- Zhu, Lichun. "Gestión de metadatos en Federación de base de datos de red". 15 de mayo, 2012.
Lectura adicional
- Allcock, w el. (Abril de 2003). "Gridftp: extensiones de ftp para la red de protocolo". Laboratorio Nacional Argonne. 20 de abril, 2012.
- Allcock, w el.; Bresnahan, J.; Kettimuthu, R.; Link, M.; Dumitrescu, C.; Raicu, I.; Foster, I. (noviembre de 2005). "El marco rayas gridftp globus y el servidor". ACM Press. 20 de abril, 2012.
- Foster, Ian; Kesselman, Carl; Tuecke, Steven (2001). "La anatomía de la red de organizaciones virtuales escalables que permite". Revista Internacional de aplicaciones de alta rendimiento (Thousand Oaks: Sage Publications) 15 (3): 200 – 222. Doi:10.1177/109434200101500302. 10 de abril, 2012.
- Foster, Ian; Kesselman, Carl; Nick, Jeffrey M.; Tuecke, Steven (22 de junio de 2002). "La fisiología de la red: una red abierta servicios de arquitectura para la integración de sistemas distribuidos". 10 de mayo, 2012.
- Hancock, B. (2009). "Una cuadrícula de datos simple usando el sistema operativo inferno". Biblioteca Hi Tech (Emerald Group Publishing Limited) 27 (3): 382 – 392. Doi:10.1108/07378830910988513.
- Hoschek, w el.; McCance, G. (10 de octubre de 2001). "La red permitió middleware de base de datos relacional". Global Grid Forum. El 22 de abril 2012.
- Kunszt, Peter Z.; Tipo, Leanne P. (07 de julio de 2002). "El open grid services redes de datos y arquitectura". 10 de mayo, 2012.
- Moore, Reagan w. "Evolución de los conceptos de cuadrícula de datos". 10 de mayo, 2012.
- Rajkumar, Kettimuthu; Allcock, William; Calero, Lee; Navarro, John-Paul; Foster, Ian (30 de marzo de 2007). "Simposio Internacional procesamiento paralelo y distribuido (IPDPS 2007)". Long Beach: IEEE International. págs. 1 – 6. 29 de abril, 2012.
|Chapter =(ignoradoAyuda)
- Thenmozhi, N.; MADHESWARAN, M. (2011). "Mecanismo de transferencia de datos para la transferencia de datos eficiente a granel en el entorno informático de red basado en el contenido". Revista Internacional de Computación Grid y aplicaciones (IJGCA) 2 (4): 49-62. Doi:10.5121/ijgca.2011.2405. ISSN2229-3949. 28 de abril, 2012.
- Tu, Manghui; Li Peng; -Ling, Yen; Thuraisingham, Bhavani; Khan, Latifur (2010). "Asegurar la replicación de datos objetos de cuadrícula de datos". IEEE Transactions on computación confiable y segura (IEEE) 7 (1): 50 – 64. Doi:10.1109/tdsc.2008.19. 26 de abril, 2012.