Reconciliación y validación de datos
Reconciliación y validación de datos de proceso industrial, o más brevemente, validación de datos y la reconciliación (DVR), es una tecnología que utiliza la información del proceso y los métodos matemáticos para corregir automáticamente las mediciones en procesos industriales. El uso de DVR permite extraer información precisa y confiable sobre el estado de los procesos de la industria de los datos de medición crudo y produce un único conjunto consistente de datos que representa la operación de proceso más probable.
Contenido
- 1 Modelos, errores de datos y medición
- 1.1 Tipos de error
- 1.2 Necesidad de la eliminación de errores de medición
- 2 Historia
- 3 Reconciliación de datos
- 3.1 Redundancia
- 3.1.1 Ejemplo de los sistemas computables y no computables
- 3.2 Beneficios
- 3.1 Redundancia
- 4 Validación de datos
- 4.1 Filtrado de datos
- 4.2 Validación del resultado
- 4.3 Detección de error grueso
- 5 Validación de datos avanzada y la reconciliación
- 5.1 Modelos termodinámicos
- 5.2 Corrección de error grueso
- 5.3 Flujo de trabajo
- 6 Aplicaciones
- 7 Véase también
- 8 Referencias
- 9 Enlaces externos
Modelos, errores de datos y medición
Procesos industriales, por ejemplo química o termodinámico en plantas químicas, refinerías, petróleo o sitios de producción de gas o centrales, son a menudo representados por dos medios fundamentales:
- Modelos que expresan la estructura general de los procesos,
- Datos que reflejan el estado de los procesos en un momento dado en el tiempo.
Los modelos pueden tener diferentes niveles de detalle, por ejemplo uno puede incorporar masa simple o compuesto conservación saldos o más avanzados modelos termodinámicos incluyendo las leyes de conservación de energía. El modelo se puede expresar matemáticamente por un sistema lineal de ecuaciones  en las variables
en las variables  , que incorpora todas las limitaciones del sistema antes mencionado (por ejemplo las masa o calor saldos alrededor de una unidad). Una variable puede ser la temperatura o la presión en un cierto lugar en la planta.
, que incorpora todas las limitaciones del sistema antes mencionado (por ejemplo las masa o calor saldos alrededor de una unidad). Una variable puede ser la temperatura o la presión en un cierto lugar en la planta.
Tipos de error
- Errores aleatorios y sistemáticos
-

Mediciones normalmente distribuidas sin sesgo.
-

Mediciones normalmente distribuidas con sesgo.
Datos origina típicamente mediciones tomadas en diferentes lugares en todo el sitio industrial, por ejemplo temperatura, presión, flujo volumétrico tasa medidas etc.. Para entender los principios básicos de DVR, es importante primero reconocer que planta las mediciones nunca son 100% la medida correcta, es decir, raw  No es una solución del sistema no lineal
No es una solución del sistema no lineal  . Cuando utiliza mediciones sin corrección para generar saldos de planta, es común tener incoherencias. Errores de medición se pueden categorizar en dos tipos básicos:
. Cuando utiliza mediciones sin corrección para generar saldos de planta, es común tener incoherencias. Errores de medición se pueden categorizar en dos tipos básicos:
- errores aleatorios debido a la intrínseca sensor exactitud y
- errores sistemáticos (o bruto errores) con el sensor calibración o transmisión de datos defectuosos.
Errores aleatorios significa que la medición 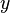 es un variable aleatoria con es decir
es un variable aleatoria con es decir  , donde es el verdadero valor que normalmente no se conoce. A error sistemático por otro lado se caracteriza por una medición que es una variable aleatoria con es decir
, donde es el verdadero valor que normalmente no se conoce. A error sistemático por otro lado se caracteriza por una medición que es una variable aleatoria con es decir 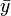 , que no es igual al valor verdadero
, que no es igual al valor verdadero 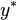 . Para facilitar la derivadas e implementar una solución de estimación óptima y basado en argumentos de que los errores son la suma de muchos factores (para que el Teorema de límite central tiene algún efecto), reconciliación de datos asume estos errores son distribuye normalmente.
. Para facilitar la derivadas e implementar una solución de estimación óptima y basado en argumentos de que los errores son la suma de muchos factores (para que el Teorema de límite central tiene algún efecto), reconciliación de datos asume estos errores son distribuye normalmente.
Otras fuentes de errores al calcular los saldos de planta incluyen fallas de proceso tales como fugas, las pérdidas de calor no modelado, propiedades físicas incorrectas u otros parámetros físicos usados en las ecuaciones y la estructura incorrecta como líneas de derivación no modelado. Otros errores incluyen dinámicas de planta no modelado como cambios de asalto y otras inestabilidades en las operaciones de la planta que violan (algebraica) modelos de estado estacionario. Adicionales dinámicas errores ocurren cuando no se toman medidas y muestras al mismo tiempo, sobre todo los análisis de laboratorio.
La práctica normal de usar medias de tiempo para los datos de entrada en parte reduce los problemas dinámicos. Sin embargo, eso no totalmente resuelve las inconsistencias de sincronización de datos muestreados infrecuentemente como análisis de laboratorio.
Este uso de los valores medios, como una media móvil, actúa como un filtro de paso bajo, así que mayormente se eliminaron ruidos de alta frecuencia. El resultado es que, en la práctica, reconciliación de datos es principalmente haciendo ajustes para corregir errores sistemáticos como sesgos.
Necesidad de la eliminación de errores de medición
ISA-95 es el estándar internacional para la integración de sistemas de control y empresa[1] Afirma:
Reconciliación de datos es un problema grave para la integración de la empresa-control. Los datos tienen que ser válidos para ser útil para el sistema de la empresa. A menudo se determinará los datos de medidas físicas que se han asociado a factores de error. Esto generalmente se debe convertir en valores exactos para el sistema de la empresa. Esta conversión puede requerir reconciliación manual, o inteligente de los valores convertidos [...]. Sistemas deben configurarse para asegurar que se envían datos precisos a la producción y de producción. Operador inadvertida o errores administrativos pueden ocasionar demasiada producción, muy poca producción, la producción mal, inventario incorrecta o falta de inventario.
Historia
DVR se ha vuelto cada vez más importante debido a los procesos industriales que se están volviendo cada vez más complejos. DVR comenzó en la década de 1960 con aplicaciones con el objetivo de cierre saldos de material en donde las mediciones de crudo estaban disponibles para todos los procesos de producción variables.[2] Al mismo tiempo el problema de la Craso error identificación y eliminación se ha presentado.[3] En la década de 1960 y 1970 variables fueron tomadas en cuenta en el proceso de reconciliación de datos.,[4][5] DVR también llegó a ser más maduro al considerar sistemas de ecuaciones no lineales generales procedentes de modelos termodinámicos.,[6] ,[7] [8] Cuasi estacionario dinámica para la estimación de parámetros de filtrado y simultáneo con el tiempo fueron introducido en 1977 por Stanley y Mah.[7] DVR dinámico fue formulado como un problema de optimización no lineal por Liebman et en 1992.[9]
Reconciliación de datos
Reconciliación de datos es una técnica que se enfoca en la corrección de errores de medición que son debido al ruido de medición, es decir errores aleatorios. Desde un punto de vista estadístico la hipótesis principal es que no errores sistemáticos existen en el conjunto de medidas, puesto que pueden sesgar los resultados de reconciliación y reducir la robustez de la reconciliación.
Dado  mediciones
mediciones 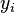 , reconciliación de datos se puede expresar matemáticamente como una problema de optimización de la siguiente forma:
, reconciliación de datos se puede expresar matemáticamente como una problema de optimización de la siguiente forma:

donde  es el valor de conciliar la
es el valor de conciliar la  (medición) -th
(medición) -th ),
),  es el valor medido de la (medición) -th),
es el valor medido de la (medición) -th),  es el
es el  -ésimo (variable)
-ésimo (variable) ), y
), y  es la desviación estándar de la (medición) -th),
es la desviación estándar de la (medición) -th),  son la
son la 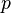 proceso de restricciones de igualdad y
proceso de restricciones de igualdad y  son los límites en las variables medidas y.
son los límites en las variables medidas y.
El término  se llama el pena de medición i. La función objetivo es la suma de las sanciones, que será denotada en el siguiente por
se llama el pena de medición i. La función objetivo es la suma de las sanciones, que será denotada en el siguiente por  .
.
En otras palabras, quiere minimizar la corrección total (medida en el término de mínimos cuadrados) que se necesita para satisfacer la limitaciones del sistema. Además, cada término de mínimos cuadrados es ponderada por el desviación estándar de la medida correspondiente.
Redundancia
- Sensor y redundancia topológica
-
Redundancia de sensor derivados de múltiples sensores de la misma cantidad al mismo tiempo en el mismo lugar.
-
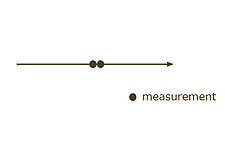
Redundancia topológica derivadas de información del modelo, mediante la restricción de conservación masiva
 , por ejemplo uno puede calcular
, por ejemplo uno puede calcular  , cuando
, cuando  y
y  son conocidos.
son conocidos.


 , por ejemplo uno puede calcular
, por ejemplo uno puede calcular Reconciliación de datos se basa fuertemente en el concepto de redundancia para corregir las mediciones lo menos posibles con el fin de satisfacer las restricciones del proceso. Aquí se define diferentemente redundancia de redundancia en teoría de la información. En cambio, redundancia surge de la combinación de los datos del sensor con el modelo (restricciones algebraicas), más concretamente a veces se llama "redundancia espacial",[7] "redundancia analítica", o "redundancia topológica".
Redundancia puede ser debido a redundancia del sensor, donde los sensores están duplicados con el fin de tener más de una medición de la misma cantidad. Redundancia también se presenta cuando una sola variable puede estimarse en varias maneras independientes de conjuntos separados de las mediciones en un tiempo determinado o con un promedio de período, usando las restricciones algebraicas.
Redundancia está vinculada al concepto de observabilidad. Una variable (o sistema) es observable si los modelos y las mediciones del sensor pueden ser utilizadas únicamente determinar su valor (estado del sistema). Un sensor es redundante si su retiro no causa ninguna pérdida de observación. Definiciones rigurosas de observabilidad, calculabilidad y redundancia, junto con los criterios para determinar, fueron establecidas por Stanley y Mah,[10] para estos casos con establecer restricciones tales como ecuaciones algebraicas y las desigualdades. A continuación, ilustramos algunos casos especiales:
Redundancia topológica está íntimamente ligada con la grados de libertad ( ) de un sistema matemático,[11] es decir, el número mínimo de piezas de información (es decir, las medidas) que se requieren para calcular todas las variables del sistema. Por ejemplo, en el ejemplo anterior el flujo de conservación requiere
) de un sistema matemático,[11] es decir, el número mínimo de piezas de información (es decir, las medidas) que se requieren para calcular todas las variables del sistema. Por ejemplo, en el ejemplo anterior el flujo de conservación requiere  . Uno tiene que saber el valor de dos de las 3 variables para calcular el tercero. En ese caso los grados de libertad para el modelo es igual a 2. Se necesitan por lo menos 2 mediciones para estimar todas las variables, y 3 se necesitaría para la redundancia.
. Uno tiene que saber el valor de dos de las 3 variables para calcular el tercero. En ese caso los grados de libertad para el modelo es igual a 2. Se necesitan por lo menos 2 mediciones para estimar todas las variables, y 3 se necesitaría para la redundancia.
Cuando se habla de redundancia topológico tenemos que distinguir entre las variables medidas y. En el siguiente Deja que nos indican por 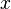 las variables y las variables medidas. Entonces se convierte en el sistema de las limitaciones del proceso
las variables y las variables medidas. Entonces se convierte en el sistema de las limitaciones del proceso  , que es un sistema no lineal en y . Si el sistema es calculable con el
, que es un sistema no lineal en y . Si el sistema es calculable con el  medidas, entonces el nivel de redundancia topológica se define como
medidas, entonces el nivel de redundancia topológica se define como  , es decir, el número de medidas adicionales que se encuentran en la cima de las medidas que se requieren para sólo calcula el sistema. Otra manera de ver el nivel de redundancia es utilizar la definición de
, es decir, el número de medidas adicionales que se encuentran en la cima de las medidas que se requieren para sólo calcula el sistema. Otra manera de ver el nivel de redundancia es utilizar la definición de  , ¿cuál es la diferencia entre el número de variables (medido y) y el número de ecuaciones. Entonces uno se pone
, ¿cuál es la diferencia entre el número de variables (medido y) y el número de ecuaciones. Entonces uno se pone

es decir, la redundancia es la diferencia entre el número de ecuaciones  y el número de variables
y el número de variables  . El nivel de redundancia total es la suma de sensor redundancia y redundancia topológica. Hablamos de redundancia positiva si el sistema es calculable y la redundancia total es positiva. Uno puede ver que el nivel de redundancia topológica sólo depende del número de las ecuaciones (las ecuaciones más cuanto mayor sea la redundancia) y el número de variables (las variables más, cuanto más baja la redundancia) y no en el número de variables medidas.
. El nivel de redundancia total es la suma de sensor redundancia y redundancia topológica. Hablamos de redundancia positiva si el sistema es calculable y la redundancia total es positiva. Uno puede ver que el nivel de redundancia topológica sólo depende del número de las ecuaciones (las ecuaciones más cuanto mayor sea la redundancia) y el número de variables (las variables más, cuanto más baja la redundancia) y no en el número de variables medidas.
Cargos simples de variables, ecuaciones y las medidas son inadecuadas para muchos sistemas, rompiendo por varias razones: (a) las partes de un sistema pueden tener redundancia, mientras que otros no y algunas porciones incluso no sería posibles calcular, y (b) no linealidades pueden conducir a conclusiones distintas en diferentes puntos de operación. Como ejemplo, considere el siguiente sistema con 4 arroyos y 2 unidades.
Ejemplo de los sistemas computables y no computables
- Sistemas computables y no computables
-
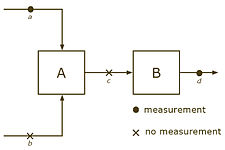
Sistema calculable, de
 uno puede computar y sabiendo rendimientos .
uno puede computar y sabiendo rendimientos . -

sistema no calculables, sabiendo
No da información sobre y .


Podemos incorporar solamente las limitaciones conservación de flujo y obtener  y
y  . Es posible que el sistema Aunque no es calculable,
. Es posible que el sistema Aunque no es calculable,  .
.
Si tenemos las medidas para  y
y  , pero no para
, pero no para  y
y 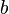 , entonces el sistema no puede calcularse (sabiendo No da información sobre y ). Por otro lado, si y son conocidas, pero no y , entonces el sistema puede ser calculado.
, entonces el sistema no puede calcularse (sabiendo No da información sobre y ). Por otro lado, si y son conocidas, pero no y , entonces el sistema puede ser calculado.
En 1981, criterios de observación y redundancia fueron probados para este tipo de flujo que implican las redes sólo masa y energía equilibrio limitaciones.[12] Después de combinar todas las planta entradas y salidas en un nodo de"medio ambiente", pérdida de observación corresponde a ciclos de corrientes. Que se observa en el segundo caso anterior, donde corrientes a y b se encuentran en un ciclo de corrientes. Redundancia clasificación sigue, por la prueba para un camino de corrientes, puesto daría lugar a un ciclo si la medida fue removida. Medidas c y d son redundantes en el segundo caso arriba, aunque parte del sistema es inobservable.
Beneficios
Redundancia puede utilizarse como una fuente de información para comprobar y corregir las mediciones e incrementar su exactitud y precisión: por un lado se reconciliaron adicionales, el problema de reconciliación de datos presentado anteriormente también incluye variables . Basado en redundancia de información, las estimaciones de estas variables pueden calcularse junto con sus exactitudes. En los procesos industriales estas variables que proporciona la reconciliación de datos se denominan sensores suaves o sensores virtuales, donde no están instalados los sensores de hardware.
Validación de datos
Validación de datos indica todas las acciones de validación y verificación antes y después del paso de reconciliación.
Filtrado de datos
Filtrado de datos indica el proceso de tratamiento de datos medidos tales que los valores se convierten en significativos y se encuentran dentro del rango de valores esperados. Filtrado de datos están necesarios antes del proceso de reconciliación con el fin de aumentar la robustez del paso de reconciliación. Hay varias maneras de datos filtrado, por ejemplo tomando la media de varios valores medidos durante un período de tiempo bien definido.
Validación del resultado
Resultado de la validación es el conjunto de validación o verificación de las medidas adoptadas tras el proceso de reconciliación y toma en cuenta medido y variables, así como conciliar los valores. Validación del resultado cubre, pero no se limita a, análisis de pena para determinar la fiabilidad de la reconciliación o controles enlazados para asegurar que los valores reconciliados mienten en un cierto rango, por ejemplo la temperatura tiene que ser dentro de unos límites razonables.
Detección de error grueso
Validación del resultado puede incluir pruebas estadísticas para validar la confiabilidad de los valores reconciliados, comprobando si errores gruesos existen en el conjunto de valores medidos. Estas pruebas pueden ser por ejemplo
- el chi cuadrado de prueba (global)
- la prueba individual.
Si no brutos existen errores en el conjunto de los valores medidos, entonces cada término de la pena en la función objetivo es una variable aleatoria se distribuye normalmente con media igual a 0 y varianza igual a 1. Por consiguiente, la función objetivo es una variable aleatoria que sigue una distribución Ji-cuadrada, puesto que es la suma del cuadrado de variables aleatorias normalmente distribuidas. Comparando el valor de la función objetivo  con un determinado percentil
con un determinado percentil  la función de densidad de probabilidad de una Chi-cuadrado distribución (por ejemplo el percentil 95 para una confianza del 95%) da una indicación de si existe un error: Si
la función de densidad de probabilidad de una Chi-cuadrado distribución (por ejemplo el percentil 95 para una confianza del 95%) da una indicación de si existe un error: Si  , entonces no brutos existen errores con 95% de probabilidad. La prueba de chi cuadrado da sólo una indicación aproximada acerca de la existencia de errores gruesos, y es fácil de realizar: sólo hay que comparar el valor de la función objetivo con el valor crítico de la distribución de chi cuadrado.
, entonces no brutos existen errores con 95% de probabilidad. La prueba de chi cuadrado da sólo una indicación aproximada acerca de la existencia de errores gruesos, y es fácil de realizar: sólo hay que comparar el valor de la función objetivo con el valor crítico de la distribución de chi cuadrado.
La prueba individual compara cada término de la pena en la función objetivo con los valores críticos de la distribución normal. Si el -ésimo término de pena está fuera del intervalo de confianza del 95% de la distribución normal, entonces no hay razón para creer que esta medida tiene un error.
Validación de datos avanzada y la reconciliación
Avanzadas de validación de datos y la reconciliación (DVR) es un enfoque integrado de combinar la reconciliación de datos y técnicas de validación de datos, que se caracteriza por
- modelos complejos, incorporando además de balances de masa también termodinámica, impulso balances, las limitaciones de equilibrios, hidrodinámica, etc..
- técnicas de remediación error grueso para asegurar la significación de los valores de conciliados
- robustos algoritmos para resolver el problema de la reconciliación.
Modelos termodinámicos
Los modelos simples incluyen balances de masa. Cuando se agregan restricciones termodinámicas tales como balances de calor el modelo, su alcance y el nivel de redundancia aumenta. En efecto, como hemos visto anteriormente, el nivel de redundancia se define como  , donde
, donde  es el número de ecuaciones. Incluida la energía saldos significa agregar ecuaciones al sistema, que se traduce en un mayor nivel de redundancia (siempre que suficientes medidas están disponibles, o equivalente, no hay demasiadas variables son).
es el número de ecuaciones. Incluida la energía saldos significa agregar ecuaciones al sistema, que se traduce en un mayor nivel de redundancia (siempre que suficientes medidas están disponibles, o equivalente, no hay demasiadas variables son).
Corrección de error grueso

Errores gruesos son errores sistemáticos de medición que puede sesgo los resultados de la reconciliación. Por lo tanto, es importante identificar y eliminar estos errores gruesos en el proceso de reconciliación. Después de la reconciliación pruebas estadísticas puede ser aplicado que indicar o no un error existe en algún lugar en el conjunto de medidas. Estas técnicas de corrección de error grueso se basan en dos conceptos:
- eliminación de Craso error
- relajación Craso error.
Eliminación de Craso error determina una medida que está sesgada por un error sistemático y descarta esta medida a partir del conjunto de datos. La determinación de la medida a ser desechada se basa en diferentes tipos de términos de pena que expresan cuánto los valores medidos se desvían de los valores reconciliados. Una vez que se detectan los errores gruesos son descartados de las mediciones y la reconciliación puede hacerse sin estas mediciones incorrectas que estropean el proceso de reconciliación. Si es necesario, la eliminación se repite hasta que no Craso error existe en el conjunto de medidas.
Objetivos de relajación Craso error en la estimación de la incertidumbre de las mediciones sospechosas de relajación así el valor conciliado en el intervalo de confianza del 95%. Relajación general encuentra aplicación cuando no es posible determinar en qué medida alrededor de una unidad es responsable por el error grueso (equivalencia de errores gruesos). Luego se aumentan las incertidumbres de medición de las mediciones involucradas.
Es importante señalar que la corrección de errores gruesos reduce la calidad de la reconciliación, las disminuciones de redundancia (eliminación) o la incertidumbre de la medida. Por lo tanto puede sólo ser aplicada cuando el nivel inicial de redundancia es lo suficientemente alto para asegurarse de que la reconciliación de datos todavía se puede hacer (vea la sección 2,[11]).
Flujo de trabajo
Soluciones avanzadas de DVR ofrecen una integración de las técnicas mencionadas anteriormente:
- adquisición de datos del historiador de datos, entradas manual o base de datos
- validación de datos y filtrado de las mediciones de crudo
- reconciliación de datos de las mediciones de filtrado
- verificación de resultado
- prueba de alcance
- bruto de corrección de error (y volver al paso 3)
- almacenamiento del resultado (mediciones de crudo junto con valores reconciliados)
El resultado de un procedimiento avanzado de DVR es un conjunto coherente de datos de proceso validado y reconciliados.
Aplicaciones
DVR encuentra aplicación principalmente en sectores donde tampoco las mediciones no son exactos o incluso inexistente, como por ejemplo en el sector aguas arriba donde Medidores de flujo es difícil o costoso de posición (véase [13]); o donde datos precisos son de alta importancia, por ejemplo por razones de seguridad en plantas de energía nuclear (véase [14]). Otro campo de aplicación es rendimiento y monitoreo de procesos (véase [15]) en refinerías de petróleo o en la industria química.
Como DVR permite para calcular las estimaciones incluso para las variables de una manera fiable, la sociedad alemana de ingeniería (VDI Gesellschaft Energie und Umwelt) ha aceptado la tecnología DVR como un medio para reemplazar costosos sensores en la industria de energía nuclear (véase la norma VDI 2048,[11]).
Véase también
- Simulación de procesos
- Análisis Pinch
- Procesos industriales
- Ingeniería Química
Referencias
- ^ "ISA-95: el estándar internacional para la integración de sistemas de control y empresa". ISA-95.com.
- ^ D.R. Kuehn, H. Davidson, Control de computadora II. Matemáticas de Control, Ing. Quím. proceso 57: 44 – 47, 1961.
- ^ V. Vaclavek, Estudios de ingeniería de sistema. Sobre la aplicación del cálculo de las observaciones del cálculo de los saldos de ingeniería química, Recop. Checa Chem Commun 34:3653, 1968.
- ^ V. Vaclavek, M. Loucka, Selección de las medidas necesarias para la realización de Balances de masa multicomponentes en planta química, SCI. Ing. Quím. 31:1199 – 1205, 1976.
- ^ R.S.H. Mah, G.M. Stanley, D.W. Downing, La reconciliación y la rectificación de datos de inventario y flujo de proceso, IND & Ing. Quím. Proc. Des. Dev 15:175-183, 1976.
- ^ J.C. Knepper, J.W. Gorman, Análisis estadístico de los conjuntos de datos limitados, AiChE Journal 26:260 – 164, 1961.
- ^ a b c G.M. Stanley y R.S.H. Mah, Estimación de los flujos y las temperaturas en las redes de proceso, AIChE Journal 23:642 – 650, 1977.
- ^ P. Joris, B. Kalitventzeff, Validación y análisis de las mediciones de proceso, Proc. CEF 87: utilizar Comput. Ing. Quím., Italia, 41 – 46, 1987.
- ^ M.J. Liebman, T.F. Edgar, L.S. Lasdon, Reconciliación de datos eficiente y estimación de los procesos dinámicos utilizando técnicas de programación no lineal, Computadoras Ing. Quím. 16:963 – 986, 1992.
- ^ Stanley G.M. y Mah, R.S.H., observancia y redundancia en estimación de datos de proceso, ingeniería química. SCI. 36, 259 (1981)
- ^ a b c VDI-Gesellschaft Energie und Umwelt, "Guías - VDI 2048 Blatt 1 - las incertidumbres de las mediciones en pruebas de aceptación para la conversión de energía y centrales - fundamentos", Asociación de ingenieros alemanes, 2000.
- ^ Stanley G.M. y R.S.H. Mah, "redes de observación y clasificación, redundancia en proceso", ingeniería química. SCI. 36, 1941 (1981)
- ^ P. delava, E. Maréchal, B. Vrielynck, B. Kalitventzeff (1999), Modelado de una unidad de destilación de petróleo crudo en el término de reconciliación de datos con ASTM o TBP curvas como entrada directa – aplicación: petróleo crudo tren de precalentamiento, Actas de la Conferencia de ESCAPE-9, Budapest, mayo 31-junio 2, 1999, volumen complementario, p. 17-20.
- ^ Langenstein M., J. Jansky, B. Laipple (2004), Encontrando megavatios en centrales nucleares con validación de datos de proceso, Actas del ICONE12, Arlington, Estados Unidos, 25 – 29 de abril de 2004.
- ^ TH. Amand, G. Heyen, B. Kalitventzeff, Monitoreo de la planta y detección de fallas: sinergia entre la reconciliación de datos y análisis de componentes principales, Comp. y Chem, Ing. 25, p. 501-507, 2001.
- Alexander, Dave, Tannar, Dave & Wasik, Larry "Usos del sistema de información de molino reconciliación de datos dinámicos para la contabilidad exacta de energía" TAPPI Fall Conference 2007.[1]
- Rankin, J. & Wasik, L. "Reconciliación de datos dinámicos de lote pulpeo procesos (para la predicción de on-line)" Conferencia de PAPTAC primavera 2009.
- S. Narasimhan, C. Jordache, Reconciliación de datos y detección de errores graves: un uso inteligente de datos de proceso, Golf Publishing Company, Houston, 2000.
- V. Veverka, F. Madron, ' Material y el equilibrio de energía en las industrias de proceso, Elsevier Science BV, Amsterdam, 1997.
- J. Romagnoli, M.C. Sánchez, Procesamiento de datos y la reconciliación para las operaciones de proceso químico, Academic Press, 2000.
Enlaces externos
Algunos grupos de investigación trabajando en la reconciliación de datos:
- Herramientas de Software de simulación de procesos químicos y servicios, Vancouver, Canadá
- Diseño de proceso y el producto – operaciones de planta, Universidad de Oklahoma, Estados Unidos
- Instituto Indio de tecnología de Madras, India
- Laboratorio de análisis y síntesis de sistemas de químicas, Universidad de Lieja, Bélgica
- Laboratorio de sistemas de energía industrial, Lausanne, Suiza
White papers:
- Sistema de información de molino utiliza reconciliación de datos dinámicos para la contabilidad exacta de energía
- Reconciliación de datos dinámicos de lote pulpeo procesos (para la predicción de on-line)
- Papeles de reconciliación de datos, observación y redundancia
Otras Páginas
- Manchester
- Costimator
- Servicios de operador NCIC
- Basketball varonil Indiana State Sycamores
- La OMS (seccion A uno rapido y el que Sell Out)
- Muertes en septiembre de 2009
- PiYo
- North American X-15
- BRINSWORTH House
- Investigacion del American College of Rheumatology y Fundacion para la educacion
- Jugador de Laserdisc
- Lady Harriet Mary Montagu