Replicación (informática)
|
|
Este artículo incluye un lista de referencias, pero sus orígenes no están claros porque tiene insuficiente citas en línea. (Octubre de 2012) |
Replicación en Computación consiste en compartir información con el fin de garantizar la coherencia entre los recursos redundantes, tales como software o hardware componentes para mejorar la confiabilidad, tolerancia a fallos, o la accesibilidad.
Contenido
- 1 Terminología
- 1.1 Modelos de replicación en sistemas distribuidos
- 2 Replicación de bases de datos
- 3 Replicación de almacenamiento de disco
- 3.1 Implementaciones
- 4 Replicación basada en archivos
- 4.1 Capturar con un controlador del kernel
- 4.1.1 Replicación de filesystem journal
- 4.2 Replicación por lotes
- 4.1 Capturar con un controlador del kernel
- 5 Replicación de memoria compartida distribuida
- 6 Replicación de múltiples primaria y primaria-backup
- 7 Véase también
- 8 Referencias
Terminología
Uno habla de:
- replicación de datos Si los mismos datos se almacenan en múltiples dispositivos de almacenamiento,[1]
- replicación de cómputo Si la misma tarea de computación se ejecuta muchas veces.
Suele ser una tarea computacional replicados en el espacio, es decir, ejecutado en dispositivos separados, o podría ser replicado en tiempo, si se ejecuta varias veces en un solo dispositivo. Replicación en el espacio o en el tiempo a menudo está vinculada a los algoritmos de programación [2]
El acceso a una entidad replicada es típicamente uniforme con acceso a una sola entidad no replicado. La replicación se debe transparente a un usuario externo. Además, en un escenario de fracaso, un failover de réplicas se esconde tanto como sea posibles. El último se refiere a la replicación de datos con respecto a Calidad de servicio (QoS) aspectos.[3]
Científicos de la computación hablan de replicación activa y pasiva en los sistemas que replican datos o servicios:
- replicación activa se realiza mediante el procesamiento de la misma solicitud en cada réplica.
- replicación pasiva consiste en procesar cada solicitud individual en una sola réplica y luego transferir su estado resultante a las otras réplicas.
Si en cualquier momento una réplica principal es designado para procesar todas las solicitudes, entonces estamos hablando de la primaria-backup esquema)maestro / esclavo esquema) predominante en clusters de alta disponibilidad. En el otro lado, si cualquier réplica procesa una solicitud y luego distribuye un nuevo estado, entonces esto es un primarias múltiples esquema (denominado multi-master en el campo de la base de datos). En el esquema múltiple primario, alguna forma de control de concurrencia distribuido debe utilizarse, tales como Administrador de bloqueos distribuido.
Balanceo de carga difiere de la duplicación de tareas, puesto que distribuye una carga de diferentes (no es lo mismo) los cálculos a través de máquinas y permite un cálculo individual a ser soltada en caso de fallo. Balanceo de carga, sin embargo, a veces utiliza la replicación de datos (especialmente múltiples maestra replicación) internamente, para distribuir sus datos entre las máquinas.
Copia de seguridad difiere de la replicación en que guarda una copia de los datos sin cambios durante un largo periodo de tiempo.[citación necesitada] Réplicas, por el contrario, se someten a actualizaciones frecuentes y perder rápidamente cualquier estado histórico. La replicación es uno de los temas más antiguos e importantes en el área general de sistemas distribuidos.
Si uno replica los datos o cómputo, el objetivo es tener un grupo de procesos que controlan eventos entrantes. Si replicar datos, estos procesos son pasivos y operan sólo para mantener los datos almacenados, responder a solicitudes de lectura y aplicar las actualizaciones. Cuando que replicar el cómputo, el objetivo siempre es proporcionar tolerancia a fallos. Por ejemplo, un servicio replicado puede utilizarse para controlar un conmutador telefónico, con el objetivo de asegurar que incluso si falla el controlador primario, la copia de seguridad puede asumir sus funciones. Pero las necesidades subyacentes son los mismos en ambos casos: asegurándose de que las réplicas de ven los mismos eventos en órdenes equivalentes, se quedan en Estados coherentes y por lo tanto, cualquier réplica puede responder a las consultas.
Modelos de replicación en sistemas distribuidos
Existe un número de modelos ampliamente citados para replicación de datos, cada uno con sus propias propiedades y rendimiento:
- Replicación transaccional. Este es el modelo para replicar datos transaccionales, por ejemplo, una base de datos o alguna otra forma de estructura de almacenamiento transaccional. El una copia serializabilidad modelo se emplea en este caso, que define los resultados legales de una transacción de datos replicados con arreglo a la general ÁCIDO propiedades que buscan garantizar sistemas transaccionales.
- Máquina estatal replicación. Este modelo asume que el proceso de replicado es un autómata finito determinista y eso emisión atómica de cada evento es posible. Se trata de un problema de computación distribuido llamado consenso distribuido y tiene mucho en común con el modelo de replicación transaccional. Esto se utiliza a veces erróneamente como sinónimo de replicación activa. Máquina estatal replicación generalmente se implementa mediante un registro replicado que consta de múltiples rondas posteriores de la Algoritmo de Paxos. Esto fue popularizado por sistema gordita de Google y es la base detrás de la abrir-fuente Almacén de datos de Keyspace.[4][5]
- Sincronía virtual. Este modelo computacional se utiliza cuando un grupo de procesos cooperar para replicar datos en memoria o para coordinar acciones. El modelo define una entidad distribuida llamada un Grupo de proceso. Un proceso puede unirse a un grupo y está dotado de un control que contiene el estado actual de los datos replicados por los miembros del grupo. Procesos pueden entonces enviar multidifusiones al grupo y verán multidifusiones entrantes en el orden idéntico. Cambios en la membresía son manejados como un especial multicast que proporciona un nuevo vista de membresía a los procesos en el grupo.
Replicación de bases de datos
Base de datos la replicación se puede utilizar en muchos sistemas de gestión de base de datos, generalmente con una relación maestro/esclavo entre el original y las copias. El maestro registra las actualizaciones, que luego la ondulación a través de los esclavos. El esclavo salidas un mensaje indicando que ha recibido la actualización con éxito, permitiendo el envío (y potencialmente reenvío hasta aplicado con éxito) de las actualizaciones subsiguientes.
Replicación de múltiples maestra, donde las actualizaciones pueden presentarse a cualquier nodo de la base de datos y luego ondulación a través de otros servidores, a menudo se desea, pero introduce aumenten sustancialmente los costos y la complejidad que puede hacer impracticable en algunas situaciones. El desafío más común que existe en la replicación de múltiples maestra es la prevención de conflictos transaccional o resolución. Más soluciones de replicación sincrónica o ansiosos en conflicto la prevención, mientras que soluciones asincrónicas de resolución de conflictos. Por ejemplo, si un disco se modifica simultáneamente en dos nodos, un sistema de replicación ansiosos detectar el conflicto antes de confirmar el compromiso y cancelar una de las transacciones. A replicación perezosa sistema permitiría que ambas transacciones cometer y ejecutar una resolución de conflictos durante la resincronización. La resolución de tal conflicto puede basarse en una fecha y hora de la transacción, en la jerarquía de los nodos de origen o en la lógica mucho más compleja, que decide sistemáticamente en todos los nodos.
Replicación de base de datos se torna difícil cuando escala. Generalmente, la escala va con dos dimensiones horizontales y verticales: escalado horizontal tiene más réplicas de datos, escalado vertical tiene réplicas de datos ubicadas más lejos en la distancia. Problemas planteados por el escalado horizontal pueden ser aliviados por un protocolo de acceso de múltiples vistas de múltiples capas. Escalado vertical causa menos problemas en la fiabilidad de internet y están mejorando el rendimiento.[6]
Cuando los datos se reproducen entre los servidores de bases de datos, para que la información permanece constante a lo largo del sistema de base de datos y usuarios no pueden decir ni siquiera sabe qué servidor en el DBMS están utilizando, el sistema se dice que exhiben transparencia de replicación.
Replicación de almacenamiento de disco
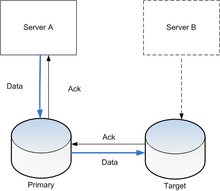
Replicación de almacenamiento activo (tiempo real) generalmente se implementa mediante la distribución de las actualizaciones de un dispositivo de bloque a varios físicos discos duros. De esta manera, cualquier sistema de archivos apoyado por el Sistema operativo pueden ser replicados sin modificaciones, como el archivo de código del sistema trabaja en un nivel por encima de la capa de controlador del dispositivo de bloque. Es implementado en hardware (en un controlador de matriz de disco) o en el software (en un controlador de dispositivo).
El método más básico es espejado de discos, típico de los discos conectados localmente. La industria del almacenamiento de información reduce las definiciones, así espejado es una operación local (corta distancia). A replicación es extensible a través de un red informática, así que los discos pueden estar ubicados en lugares distantes físicamente, y generalmente se aplica el modelo de replicación de base de datos maestro-esclavo. El propósito de replicación es prevenir daño de fallas o desastres pueden ocurrir en un solo lugar, o en caso de que se produzcan tales eventos, mejorar la capacidad de recuperarse.[7] Para la replicación, la latencia es el factor clave porque tampoco determina cuán lejos aparte los sitios pueden ser o el tipo de replicación que se puede emplear.
La principal característica de tal replicación entre sitios es cómo se manejan las operaciones de escritura:
- Síncrono replicación - garantiza "cero pérdida de datos" por medio de atómico operación de escritura, es decir, escribir o completa en ambos lados o en absoluto. Escritura no se considera completa hasta el reconocimiento por el almacenamiento local y remoto. Mayoría de las aplicaciones espera para que una operación de escritura completar antes de proceder con más trabajo, por lo tanto el rendimiento general disminuye considerablemente. Inherentemente, rendimiento cae proporcionalmente a distancia, como latencia es causada por velocidad de la luz. Para la distancia de 10 km, la más rápida posible ida y vuelta toma 67 μs, mientras que en la actualidad una escritura en la memoria caché local todo termina en sobre 10-20 μs.
- Un aspecto a menudo pasado por alto de replicación sincrónica es el hecho de que el fracaso de control remoto réplica, o incluso la interconexión, paradas por definición toda escribe (congelación del sistema de almacenamiento local). Este es el comportamiento que garantiza la pérdida de datos. Sin embargo, muchos sistemas comerciales en tal punto potencialmente peligroso No congelar, pero sólo proceder con las escrituras locales, perdiendo el cero deseado objetivo de punto de recuperación.
- La principal diferencia entre replicación sincrónica y asincrónica volumen es que la replicación sincrónica necesita esperar a que el servidor de destino en cualquier operación de escritura.[8]
- Asincrónica replicación - escritura se considera completa tan pronto como almacenamiento local lo reconoce. Almacenamiento remoto se actualiza, pero probablemente con un pequeño lag. Se incrementa el rendimiento, pero en caso de perder un almacenamiento local, el almacenamiento remoto no está garantizado que la copia actual de datos y pueden perderse datos más recientes.
- Replicación sincrónica semi - esto generalmente significa[citación necesitada] que una escritura se considera completa tan pronto como almacenamiento local reconoce un servidor remoto y reconoce que ha recibido la escritura en la memoria o en un archivo de registro dedicado. La escritura remota real no se realiza inmediatamente pero es asíncrona, lo que resulta en mejor rendimiento que la replicación sincrónica sino no ofrecer ninguna garantía de durabilidad.
- Replicación de Point-in-time - introduce periódica instantáneas se replican en lugar de almacenamiento de información primario. Si las instantáneas replicadas están basadas en punteros, entonces durante la replicación sólo los datos cambiados se mueven todo el volumen. Usando este método, la replicación puede ocurrir sobre enlaces de ancho de banda más pequeños, menos costosos tales como iSCSI o T1 en lugar de las líneas de fibra óptica.
A los límites impuestos por la latencia, técnicas de dirección Optimización de la WAN puede aplicarse al enlace.
Implementaciones
Muchos sistemas distribuidos de archivos usar replicación para asegurar la tolerancia a fallos y evitar un punto único de falla. Ver las listas de sistemas de archivos distribuidos tolerantes a fallos y sistemas de archivos tolerantes paralelo distribuido.
Otro software de replicación de almacenamiento incluye:
- CA - ARCserve Replicación y alta disponibilidad RHA
- Dell - AppAssure Compellent remoto Instant Replay y backup (replicación y recuperación ante desastres)
- EMC - EMC RecoverPoint, EMC SRDF y EMC VPLEX
- EnduraData Replicación de horario y tiempo real
- DataCore SANsymphony y SANmelody
- StarWind iSCSI SAN y NAS
- StorMagic SvSan replicación de iSCSI virtual Appliance para vSphere & HyperV
- FalconStor Replicación y espejado (sub-bloque heterogéneo point-in-time, async, sincronización)
- FreeNAS -Replicación manejado por ssh + zfs sistema de archivos [9]
- Hitachi TrueCopy
- Hewlett-Packard -Acceso continuo (HP CA)
- IBM - Peer to Peer Remote Copy (PPRC), Global Mirror y Extended Remote Copy (XRC), conocidos como IBM Copy Services
- Linbit - DRBD -abrir la replicación a nivel de bloque fuente para Linux
- HAS DRBD-como solución Open Source para FreeBSD.
- MapR volumen espejado
- NEC– DDR/RDR
- NetApp - SyncMirror y SnapMirror
- Symantec Veritas Volume Replicator (IVV)
- VMware -Site Recovery Manager (SRM) [10]
Replicación basada en archivos
Replicación basada en archivos es replicar archivos a un nivel lógico más que replicar a nivel de bloque de almacenamiento de información. Hay muchas maneras de realizar esto. A diferencia con replicación a nivel de almacenamiento de información, las soluciones confían casi exclusivamente en el software.
Capturar con un controlador del kernel
Con el uso de un controlador del kernel (específicamente un controlador de filtro), que intercepta las llamadas a las funciones del sistema de archivos, cualquier actividad es capturada inmediatamente como ocurre. Esto utiliza el mismo tipo de tecnología que emplean las damas virus activo de tiempo real. En este nivel, las operaciones de archivo lógico son capturadas como abrir archivo, escribir, borrar, etc. El controlador del kernel transmite estos comandos a otro proceso, generalmente sobre una red para una máquina diferente, que simulará las operaciones de la máquina de la fuente. Como replicación de almacenamiento de nivel de bloque, la replicación a nivel de archivo permite modos tanto sincrónicos y asincrónicos. En modo sincrónico, escribir las operaciones en la máquina de la fuente se celebró y no permite que se produzca hasta que la máquina de destino ha reconocido el éxito de la réplica. El modo sincrónico es menos común con productos de replicación de archivos, aunque existen algunas soluciones.[11]
Solución de replicación a nivel de archivos unos beneficios. En primer lugar porque los datos se capturan a un nivel de archivo puede hacer una decisión informada sobre si se debe replicar basado en la ubicación del archivo y el tipo de archivo. Por lo tanto, a diferencia de replicación de almacenamiento de nivel de bloque donde debe replicar un volumen entero, productos de replicación de archivos tienen la capacidad de excluir archivos temporales o partes de un sistema de ficheros que no contienen ningún valor para el negocio. Esto puede substancialmente reducir la cantidad de datos enviados desde la máquina de la fuente así como disminuir la carga de almacenamiento de la máquina de destino. Un beneficio adicional a la disminución de ancho de banda es los datos transmitidos pueden ser más granulares que con replicación a nivel de bloque. Si una aplicación escribe 100 bytes, sólo los 100 bytes transmitidos no un disco completo bloque que generalmente es 4096 bytes.
Por un lado negativo, ya que es una solución de software única, requiere implementación y mantenimiento a nivel de sistema operativo y utiliza algunos de potencia de procesamiento de la máquina (CPU).
Implementaciones de notables:
- CA ARCserve Replicación
- Hitachi Datos Instance Manager (anteriormente Software Cofio AIMstor[12])
- Double-Take Software Disponibilidad de
- EDpCloud Software Replicación EDpCloud tiempo Real
- Evidian SafeKit Replicación, alta disponibilidad y balanceo (de cargareplicación sincrónica archivos de nivel de byte con failover)
Replicación de filesystem journal
En muchos sentidos funcionando como un diario de la base de datos, muchos sistemas de archivos tienen la capacidad de diario de su actividad. El diario puede enviarse a otra máquina periódicamente o en tiempo real. Allí puede ser utilizado para reproducir eventos.
Implementaciones de notables:
- Microsoft DPM (actualizaciones periódicas, no en tiempo real)
Replicación por lotes
Este es el proceso de comparar los sistemas de archivos de origen y de destino y asegurar que el destino coincida con la fuente. El beneficio clave es que esas soluciones son generalmente gratuitos o de bajo costo. La desventaja es que el proceso de sincronizarlos es bastante sistema intensivo, y en consecuencia este proceso generalmente funciona con poca frecuencia.
Implementaciones de notables:
- rsync
Otro ejemplo de cómo utilizar replicación aparece en memoria compartida distribuida sistemas, donde es posible que muchos nodos del sistema comparten la misma página de la memoria - que generalmente quiere decir que cada nodo tiene una copia separada (réplica) de esta página.
Replicación de múltiples primaria y primaria-backup
Muchos enfoques clásicos de replicación están basados en un modelo primario/copia de seguridad donde un dispositivo o proceso tiene control unilateral sobre uno o más procesos o dispositivos. Por ejemplo, las primarias podrían realizar un cómputo, un log de cambios a un proceso de backup (en reposo), que luego puede tomar sobre si la principal falla de streaming. Este enfoque es el más común para la replicación de bases de datos, a pesar del riesgo que si una porción del tronco se pierde durante una falla, la copia de seguridad no podría estar en un estado idéntico al primario estaba en y entonces podrían perderse las transacciones.
Una debilidad de los esquemas primarios/copia de seguridad es que en lugares donde podrían haber sido ambos procesos activos, única que en realidad está realizando operaciones. Nos estamos ganando tolerancia pero gastar dos veces como mucho dinero para obtener esta propiedad. Por esta razón, comenzando en el período alrededor de 1985, la comunidad de investigación de sistemas distribuidos comenzó a explorar métodos alternativos de replicación de datos. Una consecuencia de este trabajo fue el surgimiento de los regímenes en los que un grupo de las réplicas podría cooperar, con cada copia del proceso a los demás y cada manipulación alguna parte de la carga de trabajo.
Jim Gray, una figura[13] dentro de la comunidad de base de datos, analizar los esquemas de replicación multi primario bajo el modelo transaccional y finalmente publicó un documento ampliamente citado escéptico del enfoque"Los peligros de la replicación y una solución". En pocas palabras, argumentó a menos que los datos se divide en alguna forma natural para que la base de datos puede ser tratado como n desunido sub bases de datos, conflictos de control de concurrencia se traducirá en rendimiento seriamente degradado y el grupo de réplicas probablemente se ralentizará en función de n. De hecho, él sugiere que los enfoques más comunes son propensos a ocasionar la degradación que escala como O(n³). Su solución, que consiste en los datos de la partición, sólo es viable en situaciones donde datos en realidad tienen una llave particionada natural.
La situación no es siempre tan sombría. Por ejemplo, en el período 1985-1987, la sincronía virtual modelo fue propuesto y emergió como un estándar ampliamente adoptado (fue utilizado en el kit de herramientas de Isis, Horus, Transist, Ensemble, Totem, Propagación, C-Ensemble, sistemas de Phoenix y Quicksilver, y es la base para el estándar de computación tolerante a fallas CORBA; el modelo se utiliza también en IBM Websphere para replicar la lógica de negocio y Windows Server 2008 de Microsoft empresa de clustering tecnología). Sincronía virtual permite un enfoque múltiple primario en el que un grupo de procesos cooperan para paralelizar algunos aspectos del procesamiento de la solicitud. El esquema puede usarse sólo para algunas formas de datos en memoria, pero cuando sea factible, proporciona aceleraciones lineales en el tamaño del grupo.
Una serie de productos modernos de apoyar programas similares. Por ejemplo, la Kit de herramientas de difusión apoya este mismo modelo virtual sincronía y puede utilizarse para implementar un esquema de replicación multi primario; también sería posible utilizar C-Ensemble o Quicksilver de esta manera. WANdisco permite la replicación activa donde cada nodo en una red es una copia exacta o réplica y por lo tanto, cada nodo de la red está activa al mismo tiempo; Este esquema está optimizado para su uso en un red de área amplia.
Véase también
- Captura de datos de cambio
- Computación en la nube
- Cluster (informática)
- Administrador de clúster
- Failover
- Sistema tolerante a fallos
- Trasvase de registros
- Replicación optimista
- Grupo de proceso
- Software de memoria transaccional
- Transparencia
- Sincronía virtual
Referencias
- ^ "¿Qué es la replicación de bases de datos? -Definición de WhatIs.com ". Searchsqlserver.TechTarget.com. 2014-01-12.
- ^ Mansouri, Najme, GholamHosein Dastghaibyfard y Ehsan Mansouri. "Combinación de replicación de datos y el algoritmo de planificación para mejorar la disponibilidad de datos en redes de datos". Revista de la red y aplicaciones informáticas (2013)
- ^ V. Andronikou, K. Mamouras, K. Tserpes, D. Kyriazis, T. Varvarigou, Replicación de datos consciente de QoS dinámico en entornos de red, Elsevier futuro generación informática - el International Journal de Grid Computing y eScience, 2012
- ^ Marton Trencseni, Attila Gazso (2009). "Keyspace: A consistentemente replicados, altamente disponible tienda de clave y valor". 2010-04-18.
- ^ Mike Burrows (2006). "El servicio de bloqueo gordita para sistemas distribuidos libremente acoplados". 2010-04-18.
- ^ Dragan Simic; Srecko Ristic; Slobodan Obradovic (abril de 2007). "Medición de los niveles de rendimiento alcanzados de las aplicaciones WEB con base de datos relacional distribuida" (PDF). Electrónica y energética 20 (1). Facta Universitatis. p. 31-43. 30 de enero 2014.
- ^ Hamilton, James. "Inter-Datacenter replicación & Geo-redundancia". Blog de James Hamilton. 20 de julio 2011.
- ^ Base de datos abierta-E. "¿Cuál es la diferencia entre replicación asincrónica y sincrónica volumen?" 12 de agosto de 2009.
- ^ "Las tareas de replicación - FreeNAS". Doc.FreeNAS.org. 2013-12-18. 2014-01-12.
- ^ "VMware vCenter Site Recovery Manager 5.1 Biblioteca de documentación". Pubs.VMware.com. 2014-01-12.
- ^ Replicación AIMstor
- ^ Bigelow, Bruce (04 de octubre de 2012). "Hitachi Data Systems compra Cofio, desarrollador de Software de infraestructura". Xconomy. 12 de junio 2014.
- ^ Actas de la Conferencia Internacional ACM SIGMOD 1999 gestión de datos: SIGMOD 99, Filadelfia, PA, USA; 1 – 3 de junio de 1999, volumen 28; p. 3.