Estructuras de almacenamiento de base de datos
|
|
Este artículo No lo hace Cite cualquier referencias o fuentes. (Marzo de 2013) |
Tablas de base de datos y índices puede almacenarse en el disco en uno de un número de formas, incluyendo ordenó/desordenada archivos planos, ISAM, montón de archivos, cubos de hash, o Árboles B +. Cada formulario tiene sus propias ventajas particulares e inconvenientes. Las formas más utilizadas son árboles B + y el ISAM. Tales formas o estructuras son un aspecto del esquema general utilizado por un motor de base de datos para almacenar información.
Contenido
- 1 Desordenada
- 2 Ordenado
- 3 Archivos estructurados
- 3.1 Archivos de montón
- 3.2 Cubos de hash
- 3.3 Árboles B +
- 3.4 ISAM
- 4 Orientación de datos
Desordenada
| Esta sección requiere expansión. (Junio de 2008) |
Desordenada almacenamiento típicamente almacena los archivos en el orden que se insertan. Tal almacenamiento ofrece buena inserción eficiencia (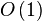 ), pero ineficiente recuperación veces ()
), pero ineficiente recuperación veces ()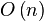 ). Normalmente estos tiempos de recuperación son mejores, sin embargo, como más bases de datos de los índices de uso en el claves primarias, dando lugar a tiempos de recuperación de
). Normalmente estos tiempos de recuperación son mejores, sin embargo, como más bases de datos de los índices de uso en el claves primarias, dando lugar a tiempos de recuperación de 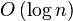 o para las teclas que son las mismas que la base de datos fila desplazamientos dentro del sistema de almacenamiento.
o para las teclas que son las mismas que la base de datos fila desplazamientos dentro del sistema de almacenamiento.
Ordenado
| Esta sección requiere expansión. (Junio de 2008) |
Ordenado almacenamiento de información típicamente almacena los registros en orden y tendrá que reorganizar o aumentar el tamaño del archivo cuando se inserta un nuevo registro, resultando en una menor eficiencia de inserción. Sin embargo, almacenamiento ordenado proporciona recuperación más eficiente que los registros son previamente ordenados, resultando en una complejidad de .
Archivos estructurados
Archivos de montón
- Método más sencillo y más básico
- inserción eficiente, con nuevos registros añadido al final del archivo, proporcionando orden cronológico
- ineficiente como buscar la recuperación tiene que ser lineal
- eliminación se logra marcando registros seleccionados como "eliminado"
- requiere reorganización periódica si el archivo es muy volátil (cambiado con frecuencia)
- Ventajas
- eficiente para cargar datos a granel
- eficiente para relaciones relativamente pequeñas como se evitan gastos generales de indexación
- eficiente cuando recuperaciones implican gran proporción de registros almacenados
- Desventajas
- No eficientes para la recuperación selectiva utilizando los valores de clave, especialmente si es grande
- clasificación puede ser muy lento
- No es adecuado para las tablas volátiles
Montón archivos son listas sin ordenar registros de tamaño variable. Aunque compartiendo un nombre similar, montón archivos son ampliamente diferentes en memoria montones.[otra explicación necesitado]
Cubos de hash
- Funciones hash calcular la dirección de la página en la que el disco va a almacenar basado en uno o más campos en el registro
- funciones hash elegidas para asegurar que direcciones se distribuyen uniformemente en el espacio de direcciones
- 'ocupación' suele ser 40% al 60% del tamaño del archivo total
- Dirección única no garantizada la detección de colisiones y los mecanismos de resolución de colisiones son requeridos
- Abrir abordar
- Desbordamiento encadenado/unchained
- Pros y contras
- eficiente para coincidencias exactas en campo clave
- No es adecuado para la recuperación de la gama, que requiere almacenamiento secuencial
- calcula donde el registro es almacenados basado en campos del registro
- funciones hash aseguran incluso difusión de datos
- las colisiones son posibles, así que se requiere una restauración y detección de colisiones
Árboles B +
Estos son los más utilizados en la práctica.
- Tiempo necesario para acceder a cualquier registro es el mismo porque se busca el mismo número de nodos
- Index es un índice completo y archivo de datos no tiene que ser ordenado
- Pros y contras
- estructura de datos versátil – secuencial así como el acceso aleatorio
- el acceso es rápido
- soportes exactas, gama, pieza clave y el patrón coincide con eficientemente
- archivos volátiles son manejados eficientemente porque índice es dinámico, se expande y contrae como tabla crece y se encoge
- menos adecuada para archivos relativamente estables – en este caso, es más eficiente ISAM
ISAM
| Esta sección requiere expansión. (Junio de 2008) |
Orientación de datos
Más convencional bases de datos relacionales Utilice el almacenamiento de "orientación de fila", lo que significa que todos los datos asociados con un renglon se almacenan juntos. Por el contrario, DBMS orientado a columna almacenar todos los datos de una columna dada juntos para servir a más rápidamente almacén de datos-estilo de consultas. Bases de datos de correlación son similares a fila basado en bases de datos, pero aplicar una capa de direccionamiento indirecto para asignar varias instancias del mismo valor que el mismo identificador numérico.
|
||||||||||||||||||||||||||