Integración de datos
Integración de datos consiste en combinar datos que residen en diferentes fuentes y proporcionando a los usuarios una vista unificada de estos datos.[1] Este proceso se convierte en significativo en una variedad de situaciones, que incluyen tanto comerciales (cuando necesitan dos empresas similares a fusionar sus bases de datos) y científica (la combinación de resultados de investigación de diferentes Bioinformática Dominios de repositorios, por ejemplo). Integración de datos aparece con mayor frecuencia como el volumen y la necesidad de compartir los datos existentes explota.[2] Se ha convertido en el foco de la extensa obra teórica, y numerosos problemas siguen sin resolverse. En gestión círculos, gente con frecuencia se refiere a la integración de datos como"Integración de información empresarial"(EII).
Contenido
- 1 Historia
- 2 Ejemplo
- 3 Teoría de la integración de datos
- 3.1 Definiciones
- 3.2 Procesamiento de consultas
- 4 Integración de datos en Ciencias de la vida
- 5 Véase también
- 6 Referencias
- 7 Lectura adicional
Historia


Problemas con la combinación heterogéneos fuentes de datos en una interfaz única consulta han existido durante algún tiempo. La rápida adopción de bases de datos después de la década de 1960 naturalmente condujo a la necesidad de compartir o fusionar repositorios existentes. Esta fusión puede realizarse en varios niveles en el arquitectura de base de datos.
Una solución popular es implementada basada en almacenamiento de datos (ver figura 1). El sistema de almacén extrae, transforma y cargas datos de orígenes heterogéneos en una sola vista esquema tan datos llega a ser compatibles entre sí. Este enfoque ofrece un firmemente acoplada arquitectura porque los datos se reconcilian ya físicamente en un único repositorio consultable, así que normalmente lleva poco tiempo para resolver dudas. Sin embargo, se encuentran problemas en la frescura de datos, es decir, la información en el almacén no siempre está actualizado. Así actualizar un origen de datos original puede actualizar el almacén, por consiguiente, la ETL proceso necesita la ejecución para la sincronización. También dificultades en datos construir almacenes cuando uno tiene sólo una interfaz de consulta a fuentes de datos de Resumen y no tienen acceso a los datos completos. Este problema surge con frecuencia al integrar varios servicios de consulta comercial como aplicaciones web de viajes o anuncio clasificado.
A partir de 2009[actualización] la tendencia de integración de datos ha favorecido a aflojar el acoplamiento entre los datos[citación necesitada] y proporcionando una interfaz unificada de consulta para acceso a datos en tiempo real sobre un mediada esquema (ver figura 2), que permite que la información a ser obtenido directamente de las bases de datos originales. Este enfoque se basa en las asignaciones entre el esquema mediado y el esquema de fuentes originales y transformar una consulta en consultas especializadas para que coincida con el esquema de las bases de datos originales. Tales asignaciones pueden especificarse en 2 formas: como una asignación de entidades en el esquema mediada a entidades en las fuentes originales (las"Global como vista"(GAV) enfoque), o como una asignación de entidades en las fuentes originales al esquema mediada (el"Locales como vista"(LAV) enfoque). Este último enfoque requiere inferencias más sofisticadas para resolver una consulta sobre el esquema de mediada, pero resulta más fácil añadir nuevas fuentes de datos a un esquema mediado (estable).
A partir de 2010[actualización] algunos de los trabajos de integración de datos de investigación las preocupaciones del integración semántica problema. Este problema dirige no la estructuración de la arquitectura de la integración, pero cómo resolver semántica conflictos entre los orígenes de datos heterogéneos. Por ejemplo si dos empresas fusionan sus bases de datos, ciertos conceptos y definiciones en sus respectivos esquemas como "ganancias" inevitablemente tienen significados diferentes. En una base de datos puede significar ganancias en dólares (un número de punto flotante), mientras que en la otra cosa representan el número de ventas (un entero). Una estrategia común para la resolución de estos problemas implica el uso de ontologías que defina explícitamente los términos esquema y así ayudar a resolver conflictos semánticos. Este enfoque representa integración de datos basado en ontologías. Por otro lado, el problema de la combinación de resultados de investigación de Bioinformática diferentes repositorios requiere Banco marcado de las similitudes, computado a partir de diferentes fuentes de datos, en un solo criterio como valor predictivo positivo. Esto permite que las fuentes de datos ser directamente comparables y puede integrarse incluso cuando las naturalezas de los experimentos son distintas.[3]
A partir de 2011[actualización] se determinó que los datos actuales métodos de modelado impartición el aislamiento de datos en cada arquitectura de datos en forma de islas de información y datos dispares de silos que representa cada una sistema dispar. Este aislamiento de datos es un artefacto accidental de los datos de modelado de metodología que resulta en el desarrollo de modelos de datos dispares.[4] Modelos de datos dispares, cuando instanciado como bases de datos, forman las bases de datos dispares. Han desarrollado metodologías de modelo de datos mejorada para eliminar el artefacto de aislamiento de datos y para promover el desarrollo de modelos de datos integrado.[5] [6] Una método de modelado de datos mejoradas refunde los modelos de datos por los aumento con estructurales metadatos en la forma de las entidades de datos estandarizados. Como resultado de la refundición de varios modelos de datos, el conjunto de modelos de datos refundición ahora compartirán una o más relaciones comunes que se refieren los metadatos estructurales ahora común a estos modelos de datos. Las relaciones de concordancia son un tipo de peer-to-peer de las relaciones de la entidad que se relacionan las entidades de datos estandarizados de múltiples modelos de datos. Varios modelos de datos que contienen la misma entidad de datos estándar pueden participar en la misma relación de uniformidad. Cuando los modelos de datos integrado se instancian como bases de datos y están debidamente había poblada de un conjunto común de maestro datos, entonces estas bases de datos están integrados.
Ejemplo
Considerar un aplicación web donde el usuario puede consultar una variedad de información sobre las ciudades (por ejemplo, las estadísticas de delincuencia, clima, hoteles, demografía, etc.). Tradicionalmente, la información debe almacenarse en una única base de datos con un esquema único. Pero cualquier empresa encontraría información de esta amplitud algo difícil y costoso recoger. Incluso si los recursos existen para reunir los datos, sería probables datos duplicados en bases de datos existentes de crimen, el tiempo en sitios web y los datos del censo.
Una solución de integración de datos puede solucionar este problema teniendo en cuenta estos recursos externos como vistas materializadas sobre un esquema virtual mediada, dando lugar a "la integración de datos virtual". Esto significa que los desarrolladores de aplicaciones construcción un esquema virtual — el esquema mediada— para modelar mejor los tipos de respuestas que los usuarios desean. A continuación, diseñan "envolturas" o adaptadores para cada origen de datos, tales como sitio web de base de datos y el tiempo en el crimen. Estos adaptadores simplemente transforman los resultados de la consulta local (los devueltos por las respectivas páginas web o bases de datos) en una forma fácilmente procesada para la solución de integración de datos (ver figura 2). Cuando el usuario de una aplicación consulta el esquema mediado, la solución de integración de datos transforma esta consulta en consultas apropiadas sobre las fuentes de datos correspondientes. Finalmente, la base de datos virtual combina los resultados de estas consultas en la respuesta a la consulta del usuario.
Esta solución ofrece la conveniencia de agregar nuevas fuentes por simplemente construyendo un adaptador o un módulo de software de aplicación para ellos. Contrasta con ETL sistemas o con una solución de base de datos única, que requieren integración manual de todo nuevo conjunto de datos en el sistema. Aprovechan las soluciones virtuales de ETL esquema virtual mediada para implementar la armonización de datos; por el que se copian los datos de la fuente designada "maestra" a los objetivos definidos, campo por campo. Avanzado Virtualización de datos también se construye sobre el concepto de objeto-orientado al modelado con el fin de construir esquemas virtual mediada o repositorio de metadatos virtual, utilizando radial arquitectura.
Cada origen de datos es dispar y como tal no está diseñado para soportar une confiable entre las fuentes de datos. Por lo tanto, datos virtualización así como Federación de datos depende de la coincidencia accidental de los datos para apoyar combinando datos e información de conjuntos de datos dispares. Debido a esta falta de uniformidad de valor de datos a través de fuentes de datos, el conjunto de retorno puede ser inexacta, incompleta e imposible validar.
Una solución consiste en replantear las bases de datos dispares para integrar estas bases de datos sin necesidad de ETL. Las bases de datos de refundición apoyan restricciones comunes donde puede aplicarse la integridad referencial entre bases de datos. Las refundición de las bases de datos proporcionan rutas de acceso de datos diseñados con uniformidad de valor de datos en bases de datos.
Teoría de la integración de datos
La teoría de la integración de datos[1] forma un subconjunto de la teoría de la base de datos y formaliza los conceptos subyacentes del problema en lógica de primer orden. Aplicar las teorías da indicaciones en cuanto a la viabilidad y la dificultad de integración de datos. Si bien sus definiciones pueden parecer abstractas, tienen suficiente generalidad para dar cabida a todo tipo de sistemas de integración.[citación necesitada]
Definiciones
Sistemas de integración de datos se definen formalmente como un triple  donde
donde  es el esquema global (o mediado),
es el esquema global (o mediado),  es el conjunto heterogéneo de esquemas de la fuente, y
es el conjunto heterogéneo de esquemas de la fuente, y 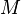 es la asignación que asigna las consultas entre la fuente y los esquemas globales. Ambos y se expresan en Idiomas sobre alfabetos compuesta por símbolos de cada uno de sus respectivos relaciones. El Mapeo consiste en afirmaciones entre consultas sobre y consultas sobre . Cuando los usuarios plantean preguntas sobre el sistema de integración de datos, que suponen las consultas sobre el mapeo y luego afirma las conexiones entre los elementos en el esquema global y los esquemas de la fuente.
es la asignación que asigna las consultas entre la fuente y los esquemas globales. Ambos y se expresan en Idiomas sobre alfabetos compuesta por símbolos de cada uno de sus respectivos relaciones. El Mapeo consiste en afirmaciones entre consultas sobre y consultas sobre . Cuando los usuarios plantean preguntas sobre el sistema de integración de datos, que suponen las consultas sobre el mapeo y luego afirma las conexiones entre los elementos en el esquema global y los esquemas de la fuente.
Una base de datos sobre un esquema se define como un conjunto de conjuntos, uno para cada relación (en una base de datos relacional). La base de datos correspondiente al esquema de fuente comprendería el conjunto de conjuntos de tuplas para cada una de las fuentes de datos heterogéneas y se llama el fuente base de datos. Tenga en cuenta que esta base de datos única fuente realmente puede representar una colección de bases de datos desconectados. La base de datos correspondiente al esquema virtual mediada se llama el base de datos global. La base de datos global debe satisfacer la asignación con respecto a la base de datos de fuente. La legalidad de esta asignación depende de la naturaleza de la correspondencia entre y . Dos formas populares de este existe correspondencia del modelo: Global como vista o GAV y Locales como vista o LAV.

GAV sistemas modelo la base de datos global como un conjunto de Vistas sobre . En este caso asociados a cada elemento de como una consulta sobre . Procesamiento de consultas se convierte en una operación directa debido a las asociaciones definidas entre y . El peso de la complejidad recae sobre implementar código mediador instruyendo el sistema de integración de datos exactamente cómo recuperar elementos de las bases de datos fuente. Si nuevas fuentes de unirse al sistema, un esfuerzo considerable puede ser necesario actualizar el mediador, así el enfoque GAV parece preferible cuando las fuentes parecen poco probable que cambie.
En un enfoque GAV el sistema de integración de datos de ejemplo anterior, el diseñador del sistema primero desarrollaría mediadores para cada una de las fuentes de información de la ciudad y luego diseñar el esquema global alrededor de estos mediadores. Por ejemplo, considere si una de las fuentes sirve un sitio Web. El diseñador es probable que luego añadir un elemento correspondiente para el clima al esquema global. Entonces la mayor parte del esfuerzo se concentra en escribir el código apropiado mediador que transformará los predicados en el tiempo en una consulta sobre el sitio Web. Este esfuerzo puede ser compleja si alguna otra fuente también se relaciona con el tiempo, porque el diseñador puede necesitar escribir código para combinar adecuadamente los resultados de las dos fuentes.
Por otro lado, en LAV, la base de datos fuente es modelada como un conjunto de Vistas sobre . En este caso asociados a cada elemento de una consulta sobre . Aquí las asociaciones exactas entre y Ya no están bien definidos. Como se ilustra en la siguiente sección, se coloca la carga de determinar cómo recuperar elementos de las fuentes en el procesador de consultas. El beneficio de un modelado de LAV es que nuevas fuentes puede ser agregado con mucho menos trabajo que en un sistema GAV, así debe ser favorecido el acercamiento LAV en casos donde el esquema mediado es menos estable o es probable que cambie.[1]
En un enfoque LAV para el sistema de integración de datos de ejemplo anterior, el diseñador del sistema diseña el esquema global primero y luego simplemente entradas los esquemas de las fuentes de información de la ciudad respectiva. Considerar otra vez si una de las fuentes sirve un sitio Web. El diseñador añadir elementos correspondientes para el tiempo en el esquema global sólo si no existía ya. Luego los programadores escriban un adaptador o contenedor para el sitio web y añadir una descripción del esquema de los resultados de los sitios web a los esquemas de la fuente. La complejidad de la adición de la nueva fuente se mueve desde el diseñador para el procesador de consultas.
Procesamiento de consultas
La teoría de procesamiento en sistemas de integración de datos de consulta se expresa comúnmente uso consuntivo consultas y Datalog, una puramente declarativo programación de la lógica idioma.[8] Uno puede pensar libremente de un consulta conjunta como una función lógica aplicada a las relaciones de una base de datos tales como" donde
donde 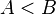 ". Si una tupla o un conjunto de tuplas se sustituye en la regla y satisface (es cierto), entonces considerar esa tupla como parte del conjunto de respuestas en la consulta. Mientras que los lenguajes formales como Datalog expresar estas consultas concisa y sin ambigüedades, común SQL consultas cuentan como conjuntivas consultas así.
". Si una tupla o un conjunto de tuplas se sustituye en la regla y satisface (es cierto), entonces considerar esa tupla como parte del conjunto de respuestas en la consulta. Mientras que los lenguajes formales como Datalog expresar estas consultas concisa y sin ambigüedades, común SQL consultas cuentan como conjuntivas consultas así.
En cuanto a la integración de datos, "contención de consulta" representa una propiedad importante de consultas conjuntivas. Una consulta  contiene otra consulta
contiene otra consulta  (denota
(denota  ) si los resultados de la aplicación son un subconjunto de los resultados de la aplicación para cualquier base de datos. Las dos consultas se dice que son equivalentes si los conjuntos resultantes son iguales para cualquier base de datos. Esto es importante porque en los sistemas tanto GAV y LAV, un usuario plantea conjuntivas consultas sobre un virtual esquema representado por un conjunto de Vistas, o "materializado" consultas conjuntivas. Integración pretende reescribir las consultas representadas por los puntos de vista para hacer sus resultados equivalentes o máximo contenidas por realiza la consulta el usuario. Esto se corresponde con el problema de responder a las consultas mediante vistas (AQUV).[9]
) si los resultados de la aplicación son un subconjunto de los resultados de la aplicación para cualquier base de datos. Las dos consultas se dice que son equivalentes si los conjuntos resultantes son iguales para cualquier base de datos. Esto es importante porque en los sistemas tanto GAV y LAV, un usuario plantea conjuntivas consultas sobre un virtual esquema representado por un conjunto de Vistas, o "materializado" consultas conjuntivas. Integración pretende reescribir las consultas representadas por los puntos de vista para hacer sus resultados equivalentes o máximo contenidas por realiza la consulta el usuario. Esto se corresponde con el problema de responder a las consultas mediante vistas (AQUV).[9]
En sistemas de GAV, un diseñador de sistemas escribe código de mediador para definir la reescritura de consultas. Cada elemento en la consulta del usuario corresponde a una regla de sustitución como cada elemento en el esquema global corresponde a una consulta sobre la fuente. Procesamiento de consultas simplemente expande los sub-metas de consulta del usuario según la regla especificada en el mediador y así la consulta resultante es probable que sea equivalente. Mientras que el diseñador como hace la mayoría de los trabajos de antemano, algunos sistemas GAV Tsimmis involucrar a simplificar el proceso de descripción de mediador.
En los sistemas de LAV, consultas sufren un proceso más radical de reescribir porque no existe ningún mediador para alinear realiza la consulta el usuario con una estrategia de expansión simple. El sistema de integración debe ejecutar una búsqueda en el espacio de posibles consultas para encontrar la mejor adaptación. La reescritura resultante puede no ser una consulta equivalente pero máximo contenido y las tuplas resultantes pueden estar incompletos. A partir de 2009[actualización] el algoritmo MiniCon[9] es el algoritmo de reescritura consulta principal para los sistemas de integración de datos LAV.
En general, es la complejidad de la reescritura de consultas NP-completo.[9] Si el espacio de reescrituras es relativamente pequeño esto no plantea un problema — incluso para integración de sistemas con cientos de fuentes.
Integración de datos en Ciencias de la vida
Preguntas a gran escala en la ciencia, tales como el calentamiento global, especies invasoras la extensión, y agotamiento de los recursos, exigen cada vez más a la colección de conjuntos de datos dispares para metanálisis. Este tipo de integración de datos es especialmente difícil para datos ecológicos y ambientales porque normas de metadatos No concuerdan sobre y allí se producen muchos tipos de datos diferentes en estos campos. Fundación Nacional de ciencia iniciativas tales como DATANET se pretende facilitar la integración de datos para los científicos proporcionando ciberinfraestructura y establecimiento de normas. Los cinco fondos DATANET las iniciativas son DataONE,[10] dirigido por William Michener en el Universidad de nuevo México; La conservación de datos,[11] dirigido por Sayeed Choudhury de Johns Hopkins University; SEAD: Medio ambiente sostenible a través de datos procesables,[12] dirigido por Margaret Hedstrom de la Universidad de Michigan; el consorcio de Federación DataNet,[13] dirigido por Reagan Moore de la Universidad de Carolina del norte; y Terra Populus,[14] dirigido por Steven Ruggles de la Universidad de Minnesota. La Alianza de datos de investigación,[15] más recientemente, ha explorado crear marcos de integración de datos globales.
Véase también
- Estructura grande
- Gestión semántica
- Integración de datos básicos
- Integración de datos del cliente
- Conservación de datos
- Fusión de datos
- Correlación de datos
- Dataspaces
- Virtualización de datos
- Almacenamiento de datos
- Datos de disputas
- Modelo de base de datos
- Datalog
- Dataspaces
- Integración de datos de borde
- Integración de aplicaciones empresariales
- Marco de arquitectura empresarial
- Integración de información empresarial (EII)
- Integración empresarial
- Extraer, transformar, carga
- Geodi:: Integración de datos geoscientific
- Integración de información
- Servidor de información
- Centro de competencias de integración
- Consorcio de integración
- JXTA
- Gestión de datos maestros
- Mapeo objeto-relacional
- Integración de datos basado en ontologías
- Open Text
- Esquema que empareja
- Integración semántica
- SQL
- Enfoque de tres esquemas
- UDEF
- Servicio Web
Referencias
- ^ a b c Maurizio Lenzerini (2002). "CÁPSULAS DE 2002". págs. 233 – 246.
|Chapter =(ignoradoAyuda) - ^ Frederick Lane (2006). IDC: Mundo creado 161 billones de gigabytes de datos en 2006 "IDC: mundo creado 161 billones de gigabytes de datos en 2006".
- ^ Shubhra S. Ray et al (2009). "La combinación de múltiples fuentes de información a través de anotación funcional basado en la ponderación: predicción de función del Gene en la levadura". IEEE Transactions on Biomedical Engineering 56 (2): 229-236. Doi:10.1109/TBME.2008.2005955. PMID19272921.
- ^ Duane Nickull (2003). "Modelado de método para armonizar los modelos de datos dispares".
- ^ Michael Mireku Kwakye (2011). "Un enfoque práctico para combinar modelos de datos Multidimensional".
- ^ "Architectural consolidación motor rápida – la solución empresarial para los modelos de datos dispares.". 2011.
- ^ Christoph Koch (2001). "La integración de datos contra múltiples evolución autónomas esquemas".
- ^ Jeffrey D. Ullman (1997). "ICDT 1997". págs. 19-40.
|Chapter =(ignoradoAyuda) - ^ a b c Alon Y. Halevy (2001). "La VLDB Journal". PP. 270 – 294.
|Chapter =(ignoradoAyuda) - ^ William Michener et al. "DataONE: red de observación de la tierra". www.Dataone.org. 19 / 01 / 2013.
- ^ Sayeed Choudhury et al. "Conservación de datos". dataconservancy.org. 19 / 01 / 2013.
- ^ Margaret Hedstrom et al. "SEAD medio ambiente sostenible - datos procesables". Sead-data.net. 19 / 01 / 2013.
- ^ Reagan Moore et al. "DataNet Federación consorcio". datafed.org. 19 / 01 / 2013.
- ^ Steven Ruggles et al. "Terra Populus: integrada de datos sobre la población y el medio ambiente". terrapop.org. 19 / 01 / 2013.
- ^ Bill Nichols. "Alianza de datos de investigación". Rd-alliance.org. 2014-10-01.
Lectura adicional
- Ronald Schuldt (15 de noviembre de 2011). UDEF – seis pasos para la integración de datos rentable. CreateSpace. ISBN978-1-4664-6762-0.
- Roberta Shauger (20 de diciembre de 2011). UDEF conceptos definidos – Guía de referencia. CreateSpace. ISBN978-1-4681-1483-6.
Otras Páginas
- Si miao wan
- Katie Holmes (categoria actrices de Toledo, Ohio)
- Miller Thomson
- Jerry Rubin (categoria personas de Echo Park, Los Angeles)
- BMW M102
- Establecimiento de la vida
- Basford, Staffordshire
- Desarrollo socio
- Diseno
- Modelado de riesgos financieros
- Lomas de Chapultepec
- Bebe colodion
- Octubre de 1915